地平线智能驾驶部宋巍:面向规模化量产的智能驾驶系统和软件开发

导读:
7月27日,地平线在智东西公开课开设的「地平线自动驾驶技术专场」第3讲顺利完结,地平线智能驾驶应用软件部负责人宋巍围绕《面向规模化量产的智能驾驶系统和软件开发》这一主题进行了直播讲解。
宋巍老师首先结合以往智能驾驶应用软件开发过程中的痛点和实践经验,对智能驾驶应用软件技术进行了详细分析。之后,他从软件视角阐述了“软硬结合”和“软硬解耦”的意义与价值,并对智能驾驶软件开发平台Horizon TogetherOS Bole™进行了深度讲解。最后,还展望了智能驾驶应用软件的开发趋势。
本次专场分为主讲和Q&A两个环节,以下则是主讲回顾:
大家晚上好,非常荣幸参与本次专场讲解,我分享的主题为《面向规模化量产的智能驾驶系统和软件开发》。

我是宋巍,来自地平线智能驾驶应用软件部,毕业于清华大学,此后的十余年专注于边缘AI应用落地, 2016年加入地平线,负责智能驾驶软件研发及团队管理,先后参与地平线各代芯片研发、应用落地及车型量产相关工作;同时,也主导了地平线首个智能驾驶前装量产项目软件开发。
今天我会从以下4个方面与大家做一些分享:
1、智能驾驶应用软件技术拆解
2、软件视角的“软硬结合”与“软硬解耦”
3、智能驾驶软件开发平台Horizon TogetherOS Bole™
4、智能驾驶应用软件开发趋势展望
1
智能驾驶应用软件技术拆解
谈到软件,那什么是软件呢?维基百科上的解释是:Software is a set of instructions and documentation that tells a computer what to do or how to perform a task。在百度百科上也给了软件中文解释,是指一系列按照特定顺序组织的计算机数据和指令的集合。对于软件来说,它就是在执行单元上执行指令和数据,也就是在硬件之上,所有事情都是软件。

在整个智能驾驶中,如果从大的领域划分,可以看到有广义感知、地图融合、规划和控制几个大领域。如果是根据算法时代来划分,可以划分成软件1.0和软件2.0。
软件1.0是传统的CV,或者是在端到端的深度学习落地之前,基于规则实现的一些面向自动驾驶的软件和算法。软件2.0是未来可以通过深度学习和数据驱动,端到端的把整个软件算法性能迭代起来。但描述它时都是用软件1.0和软件2.0,这其实是一个广义的软件定义。那对于一个智能驾驶的软件工程师来说,这时就要承载上面所有领域的研发工作。
一个软件研发工程师,他的能力要求该如何被定义呢?简单来看,因为要做嵌入式开发,懂C++就可以。但如果是面向智能驾驶业务开发的工作,那既要有丰富的软件工程能力;还要有完备的智能驾驶业务知识体系,知道智能驾驶的业务在做什么;又要对硬件有一定理解,因为在嵌入式上开发,资源和在服务器上开发是非常不一样的;且要有一定的算法实现能力,因为在开发过程中,如果对算法一无所知,整个开发过程会遇到非常多的困难。
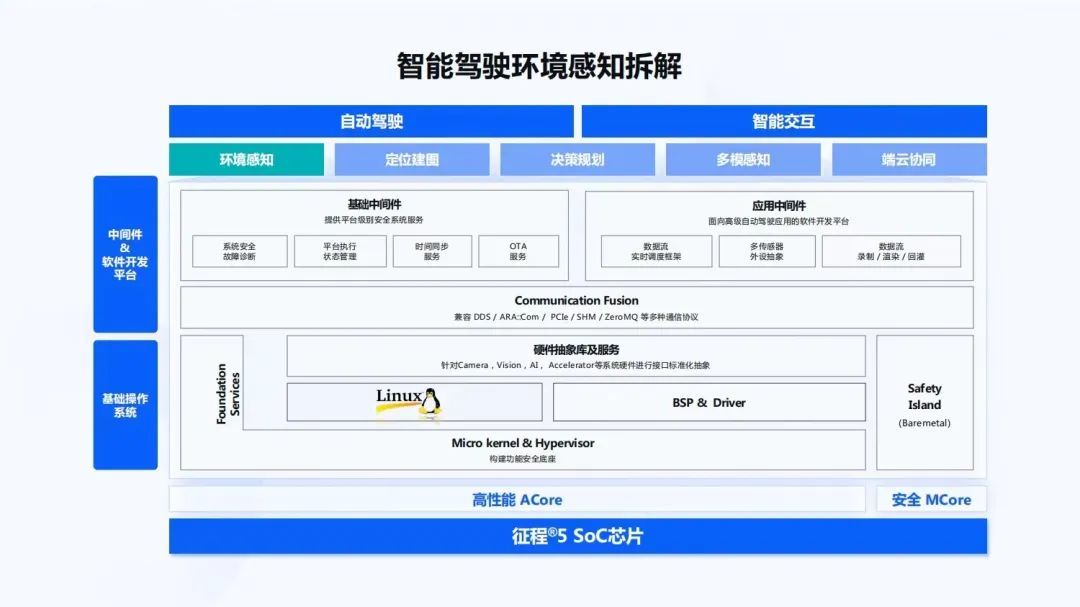
我们可以把智能驾驶的环境感知做一些拆解。从地平线征程5 SoC芯片的系统框图上,可以看到有OS部分,即基础操作系统;再往上有中间件和软件开发平台,整个通讯的组件,基础中间件和应用中间件;再往上就是面向自动驾驶和智能交互的上层应用。

主要看下环境感知部分。我们把它做一些简单的拆解,如果做环境感知,首先要有一系列的传感器,有时间同步,有摄像头、激光雷达、毫米波、超声波、车身的底盘信号、GPS/IMU等。然后,在一个嵌入式SoC上有很多的硬核,需要对硬核做一些调度,来执行模型。对模型也要做调度,比如模型的前处理、后处理。基于底盘信号,要做自测里程计,用到Odom。有了感知结果和Odom之后,会做感知结构化,进而可以做动/静态的目标重建、自车的位姿估计。
同时,为了做软件2.0,整个的数据闭环能够以数据驱动迭代算法,还要在端上做数据缓存。对于一些特定的数据做数据触发,把缓存信号再发出去。这个过程都是需要软件来做的,后面也会逐一的进行拆解:先是传感器的部分,后面讲硬核调度,然后是偏算法的Odom和感知结构化。
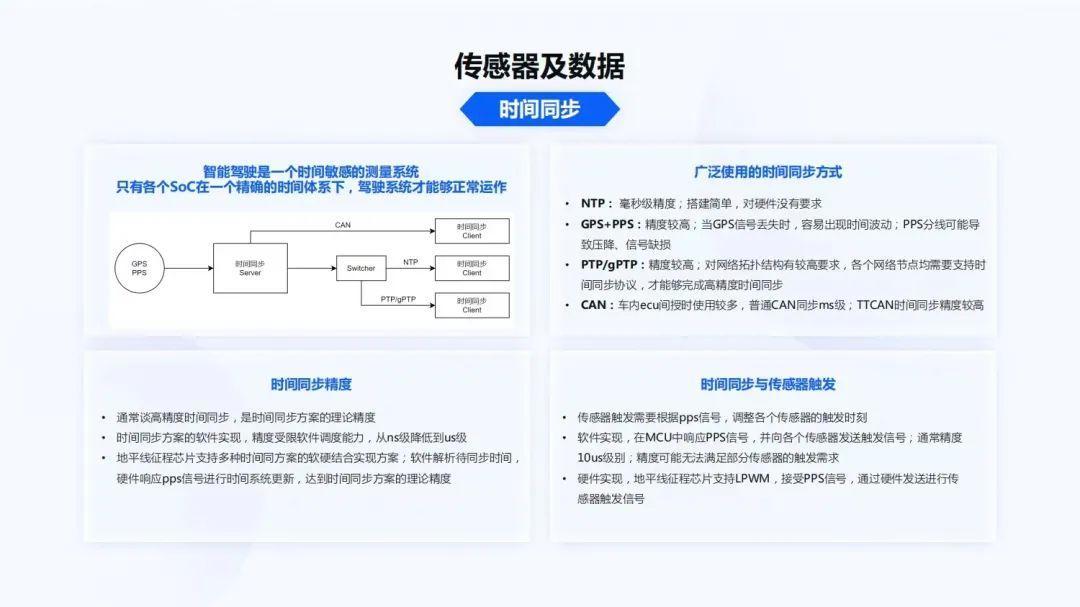
首先是传感器和数据。第一点要看的是时间同步。智能驾驶是一个时间敏感的测量系统。这里有两个词,一个是“时间敏感”,一个是“测量”。因为对于智能驾驶来说,如果时间错了50毫秒、100毫秒,整个计算结果就会有非常大的误差。同时,环境感知也是测量环境中不同目标距离自车的相对位置、速度、加速度等信息,它们对于时间都有一个非常重要的定义。只有各个SoC都在一个精确的时间体系下,智能驾驶才能够正常运作。
广泛使用的时间同步方式,有NTP。NTP通常在毫秒级精度搭建比较简单,对硬件也没有要求,但NTP通常会受网络环境波动的影响,时间调整会比较大。GPS+PPS用到的也比较多,虽然精度比较高,但是当GPS信号丢失时,非常容易出现时间的波动。比如在山里面经常有隧道,有的隧道比较长,过一个隧道有可能GPS信号会丢失,当GPS信号再次获取时,时间就很容易出现波动。同时,PPS信号也是时间同步非常重要的一个描述发源。如果一个系统里只有GPS和PPS,给多个触发,PPS分线也会导致一些压降、信号缺损。PTP/gPTP精度比较高,但对网络拓扑结构要求也会比较高,各个网络节点均需要支持时间同步协议,才能够完成高精度的时间同步。在CAN系统里面,车内ECU间授时使用较多,普通CAN时间同步在ms级,TTCAN也会把时间同步的精度提高到微秒级精度。
如上图左上角所示,通常一个系统都会是GPS+PPS作为一个独立的时间源,之后会有一个时间同步的Server,然后作为一个Master,经过一些Switcher,然后给各个Slave节点或者Client做时间授时。
对于时间同步的精度,通常谈到的高精度时间同步是一个理论的精度。GPS理论的时间同步精度很高。如果是纯软件实现,接收一个PPS的脉冲信号时,就会受限于软件的调度能力,精度也会从ns级降低到us级。而在地平线的征程芯片中,为了能够让整个系统有更高的时间同步精度,会以软硬结合的方式实现。对于软件来说,会解析一个待同步的时间,硬件响应PPS信号,然后在硬件的方案下,直接对整个启动时间进行更新,达到时间同步方案的理论精度。
同时,由于时间同步有一个PPS,所以时间同步往往也和传感器触发相关。很多的传感器都依赖于PPS信号调整传感器的一些相位差,来达到时间同步的精度和传感器的对齐精度。
这个部分也会涉及到一些软件和硬件的差别。对于软件实现来说,通常需要在周期比较稳定的MCU中响应PPS信号,然后向各个传感器发送触发信号。而这种触发信号对于MCU来说,达到10us级就已经比较高了。但这个精度仍然无法满足部分传感器的触发要求,因为有的传感器在曝光触发时,触发条件非常高,要求触发信号在几us级别内。如果触发信号没有达到精度,有可能图像会出现一些缺损,或者图像出现一些重曝光,对后续的影响比较大。
在硬件实现方面,地平线征程芯片支持LPWM,可以接收PPS信号。通过硬件转发触发信号,也可以设置不同触发信号的相位差,达到整车传感器的时间同步对齐作用。
当把所有的SoC和传感器都做到一个时间同步精度下,下一步就看传感器。
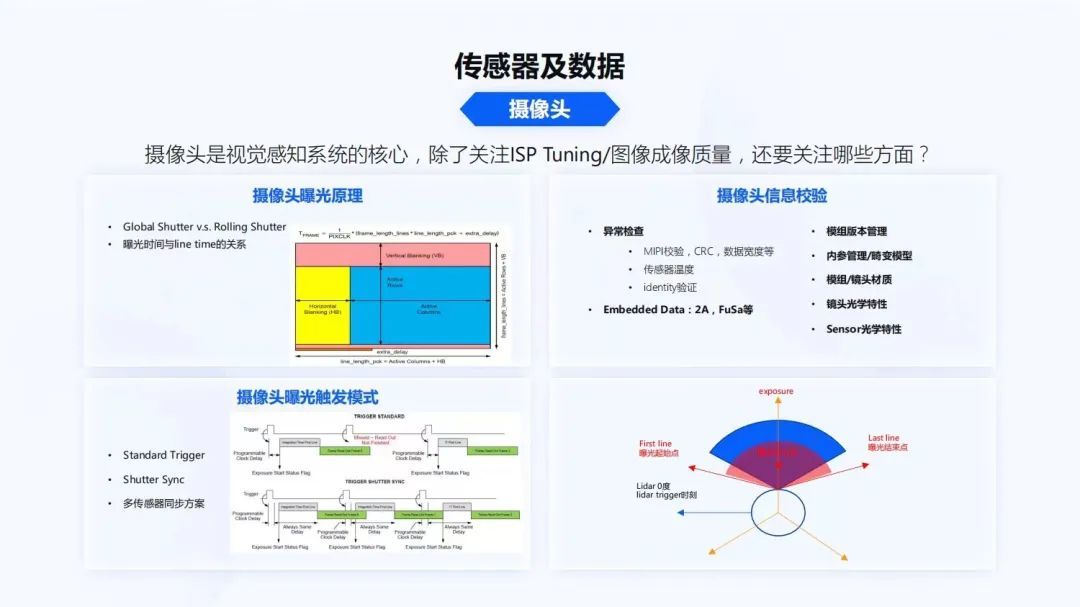
首先看摄像头,摄像头是视觉感知系统的核心。对于算法的同学,可能只关注ISP Tuning和图像的成像质量,那除此之外还需要关注哪些方面呢?
在做一些高等级的自动驾驶算法时,目前已经和过去的时代不太一样。在过去传统的视觉感知过程中,经常是由人工标记2D的bounding box,然后做模型训练。而对于未来一些3D算法,像特斯拉最近开放了很多的BEV算法,地平线也实现了BEV算法,这些算法中对摄像头的同步,及其对于时间系统的要求是非常高的。所以软件工程师和算法工程师,都需要理解摄像头的曝光原理。
Global Shutter和Rolling Shutter大家可能都会知道,但是Rolling Shutter的曝光原理到底是什么?曝光时间是我们经常提到的ISP曝光控制时间,它和每行传感器的数据生成时间到底是什么关系?一帧数据生成,比如曝光时间是10毫秒和一帧数据生成的30毫秒,关系到底是什么?传感器中间的时序到底是如何设置的?这些是后续整个算法设计,视觉和其他传感器对齐中非常重要的一点。
同时摄像头的曝光触发模式,也会是多种多样的。比如一些标准的触发模式,像Shutter Sync。刚才谈到时间同步时有PPS信号,标准触发模式一般都是接收到PPS信号,摄像头立刻曝光触发。Shutter Sync会有一个确定性的延迟,然后让数据开始往外传输。这两种模式得到的传感器时间是不一样的,它的物理的意义也是不一样的。
在做多传感器对齐时,不同的曝光模式对后续的算法和软件实现差别都会非常大。对于软件来说,一个摄像头,除了曝光原理、触发模式,还有很多其他的信息需要了解,因为对于摄像头这种高频的数据,还有很多的异常需要做检查。像高速接口MIPI很容易受到外部电磁的干扰;MIPI校验,CRC校验,每一行数据宽度的校验;有了传感器,它会有一些复杂的功能,传感器内部温度是否过高,也需要做校验。传感器是否会被人调包,算法适配的传感器是不是装错了,装成了别的型号,这时还有一些传感器的identity验证。每帧数据在效应区,如上图左上角的效应区,Embedded Data里有单帧的2A,FuSa等信息,这些都是软件开发者需要关注的事情。
对于模组来说,还要做很多管理相关的事情,像模组的版本管理。因为在量产过程中,模组也会有很多的版本,它是AA对焦的?模组的对焦是什么状态?模组的材质、Lens内参存储在什么位置?机电模型到底用的是什么?模组材质在不同的温度下,镜头内会不会起雾?Lens的光学特性,Lens会不会出现一些鬼影和擦散光?以上这些都是在自动驾驶开发过程中,软件工程师需要关注的一些点,通过这些才能够把整个系统串起来。
同时,多传感器曝光在曝光原理部分就能很好地体现出来。如上图右下角所示,一个传统的机械激光雷达,处于一个360度扫描的状态。Lidar在0时刻扫描时,摄像头到底从哪个时刻要触发曝光,到底是选择用Standard trigger还是Shutter Sync,这都是整个系统中软件工程师需要明确讨论的内容。

不同的方案对于地平线来说,从征程第2代芯片、征程第3代芯片到征程第5代芯片,它们在逐渐覆盖越来越复杂的智能驾驶系统。从1V的2M摄像头、到1V的8M摄像头,到6V,再到后面10V、11V,最终能够做一个完整的自动驾驶产品。从上图可以看出,摄像头在这里扮演着非常重要的角色,而且摄像头的复杂程度也会越来越高。对于不同的摄像头,都要理解不同摄像头的曝光原理、触发模式,各种安全校验,这是非常复杂的。
那如何简化这个过程呢?地平线有一些传感器认证的方案,经过认证方案的传感器,它们都经过前面提到的模式验证,能够很好的和地平线软件、算法、以及芯片做匹配,能够帮我们的用户,尽可能把多个 摄像头、多类型传感器更好的搭建起来。

对于激光雷达来说,有哪方面的应用呢?高阶自动驾驶可能会选择激光雷达作为感知传感器,低阶自动驾驶会使用激光雷达作为一个真值系统。而现有的2.5D/3D算法方案,都会使用激光雷达真值做自动化的数据标注方案。
激光雷达有很多不同的种类,比如有机械激光雷达,如上图左下角所示,是一个360度旋转的激光雷达。激光雷达可以接收时间同步的PPS信号来调整马达转速,让激光雷达在它的坐标系定义的0度上,和0时刻对齐。还有一些固态/半固态激光雷达,比如MEMS,在MEMS内会把它划分成多区,然后进行扫描。MEMS的好处是多区可以同时扫描,但区块之间会有一些overlap和重影。旋转镜跟机械激光雷达的精度差不多,也是旋转的形式,从左至右扫描过去。也有一些非重复的、非规则的扫描,而得到的点云对于人来说,直观理解会比较困难。也有纯固态的Flash激光雷达,激光点阵模拟camera曝光方式进行扫描。
对于激光雷达的扫描方式,也都需要时间同步。通过PPS调整激光雷达和不同摄像头曝光时刻的角度去对齐,达到右下角图所示的情况。每一个点经过时间对齐、传感器之间的标定,能够让激光雷达的点云与视觉实现一个完全对齐的方案。
激光雷达在部署过程中,也会经常会遇到很多问题。激光雷达目前主要使用UDP协议,UDP协议网络带宽的负载会比较高,使用时也需要设置网络环境/VLAN隔离;Lidar网络包比较小,一般是一个MTU发一包数据,这就会导致网络包非常多,网络中断响应也会非常多,影响整个系统的响应能力;未来征程芯片也会支持硬件网络拆包来解决这些的问题。
激光雷达在使用的过程中,也会遇到非常多的问题。虽然激光雷达的精度是比较高的,但使用过程中会碰到各种的镜面反射,你将会得到一些预期不到的点。比如地面反射到其他的地方,或者通过车窗直接反射到远处,或更远的一些相邻车,到雨、雪、雾、柳絮、脏污等。激光雷达在高速上比较不幸时,有些小虫子可能会撞上激光雷达,导致传感器出现一些故障;以及激光雷达对不同的物体,反射值也是不一样的。通常我们也会设置不同反射值的映射,对于不了解激光雷达的开发者来说,有时拿到一些反射值可能会觉得比较奇怪,为什么有的反射值这么高,有的反射值这么低。
对于非纯固态激光雷达,供电稳定性也会是一个很大的问题,在实车环境的供电系统不是特别好。如果做不到稳定的激光雷达供电,有可能也会导致光头或者机械元件出现异常,从而导致点云出现异常。同时,也需要关注多传感器对齐,这些对于软件开发来者来说,都是非常重要的工作。
激光雷达在高频的UDP数据包情况下,协议解析如何做到非常低的延迟,尽可能地降低CPU负载,都是软件开发者需要关注的事情。同时,传感器和算法之间达成一致,也是在整个自动驾驶系统软件开发过程中,需要上下游不停拉通、对齐的事情。
对于激光雷达,地平线也有很多合作伙伴,都能够比较好的支持地平线的感知系统构建及真值数据构建。

自动驾驶系统里还有很多其他的传感器。
首先,车身底盘信号从CAN或CANFD,能够拿到很多车身上其他传感器的数据。对于CAN和CANFD来说,也有很多接入方式,比如征程5代芯片上有CAN收发器,直接使用SocketCAN,来接收CAN数据。通常车上也会引入一个MCU作为网关,MCU和SoC之间,通过SPI进行CAN协议转发。这时就会出现数据链路长的问题,经过网关,SPI、OS到HAL、USER才能进行解析。
在协议中的时间敏感系统,不同的SoC之间需要保证时间同步,以及数据的时刻到底是什么,所以协议中需要对时间有非常明确的定义。然后对于CAN大小端数据的校验,Rolling Counter和CRC,各种信号的校验数据有效位、阈值、数据频率、数据更新。对于软件开发者来说,信号的校验是功能安全处理中非常重要的一点。
毫米波雷达和4D Image Radar。它们的数据链路比较多,有可能会使用CANFD,有的4D Image Radar用以太网,也有4D Image Radar用MIPI,来降低数据传输延迟。数据类型也会比较多,目前大部分Radar都是目标级的,即通常输出了跟踪之后的目标数据。也有一些Radar能够输出一些原始的雷达回波信号,从厂商获取有一定难度。4D Image Radar目前合作厂商都会得到一些点云数据,信息量与比较传统的Radar相比,有明显的提高。时间同步方面,对于不同传感器,可以通过CAN或以太网进行时间同步。
对于GPS和IMU,GPS的时间同步是授时和定位系统必备的。不同的GPS精度差异也比较大;不同型号的RTK,定位精度在5厘米、10厘米、20厘米级别;不同的IMU精度差异也比较大,有温飘。数据接口通常为UART、SPI和I2C,这些接口都是相对比较低速的,特别UART在查询时,整个数据链路都会比较慢,稳定性相对较差;而且对于IMU来说,通常不具备授时能力,IMU基于内部时钟进行数据处理;对于一个数据敏感系统不稳定的数据链路来说,需要使用IMU内部时间进行数据的时间校验和优化。
超声波雷达通常会用于一些低速的避障场景,与感知进行融合,但超声波都不具备时间同步的能力,对于低速场景来说还是可以接受的。
前面更多的是讲到传感器自身以及传感器的时间同步。多传感器以及多类型的传感器,就需要做好传感器标定。

单传感器标定方面有产线标定,通常在一辆汽车下线时,在产线中会有一个产线标定房,如上图左上角所示,这张图片是地平线的一个早期的标定间,它更多是校验自己的算法。售后标定是车可能会出现一些问题,进行一些换件,在4S店进行的标定;对于在线标定,车辆可能会有一些胎压变化,或经过长时间的热胀冷缩带来的传感器的姿态发生变化。车辆的负载变化,都需要对传感器进行在线标定以及动态标定。
多传感器标定对系统的时间精度要求非常高,如果所有的传感器不在一个时间系统下,很难获得比较精确的时间;同时,摄像头、激光雷达的扫描方式不同,需要理解多传感器数据的生产原理,保障多传感器的时间是对齐的;也要理解应该如何做传感器数据的时间补偿,如何让多传感器达到对齐的效果;最后,还需要多传感器的联合标定算法。
在这个过程中,一方面是标定算法的精度,另一方面,工程化是非常重要的,特别是在产线标定过程中,如果工程化出现了问题,产线会被block,非常影响效率。
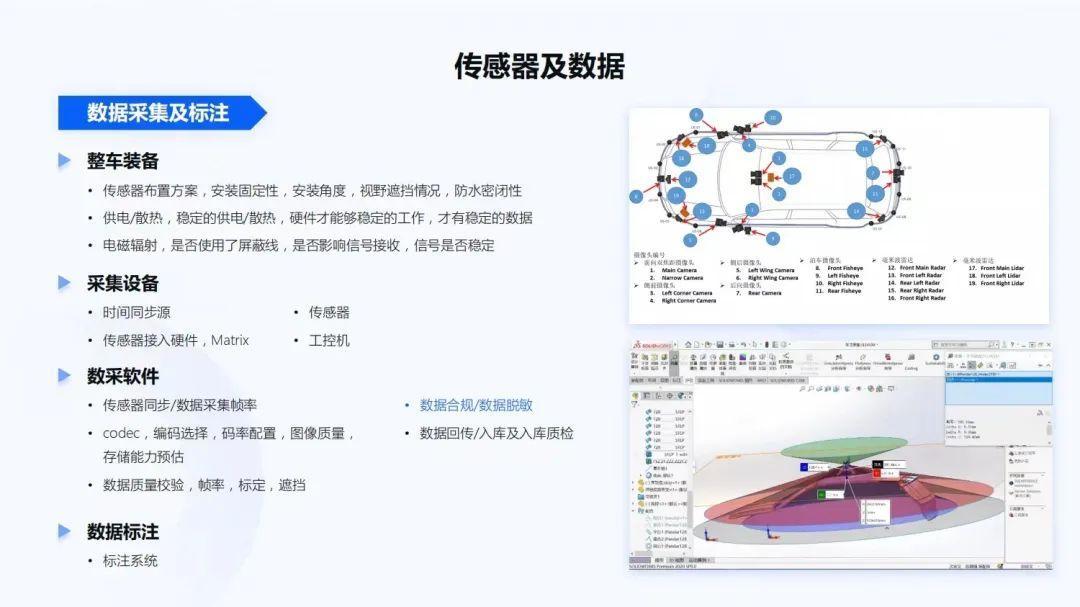
前面提到的软件和一些基础性算法都准备好之后,可以开始准备数据采集或标注,进一步打造自动驾驶系统。
在安装传感器方面,首先需要整车装备。在传感器的布置方案中,检查安装不同传感器是否足够的固定,会不会天气一热胶就软了;安装的角度和系统的需求是否一致的,是否都能够达到我们的期望。还有在安装过程中,视野是否有遮挡,比如此前经常要做一些数模方案,看传感器的感知范围内,是否会被车身所遮挡。整个安装方案是否防水密闭,像最近北京下暴雨,如果有一辆车在这种情况下开出去,传感器是否会进水。
在整车的供电和散热方面,在供电不稳定的情况下,有些传感器不能够正常工作。电磁辐射,比如整车传感器比较多,线材也比较多,是否使用一些屏蔽线,是否影响了接收信号的稳定性。
在整车的采集设备部署过程中,整车的时间同步源精度是否足够。当时间发生跳变时,时间同步方案是否能够保障整个系统仍然能够稳定的运行。传感器是否都正常的部署。对于传感器接入了硬件,像地平线Matrix自动驾驶计算平台,包括工控机也要录制所有采集到的数据。
数采软件,需要校验传感器同步以及数据采集帧率是否满足算法的要求,即数据是否满帧率。对于视觉系统来说,还要看codec编解码,究竟是选择264、265还JEPG。码率的配置、图像的质量是否满足算法的要求。不同的码率配置、不同的数据格式,对整个存储带宽的影响都特别大。未来可能经常会看到一个11V、3L、5R的智能驾驶系统,它一秒的数据量可能都会达到GB级,存储能力、磁盘写入能力是否足够,如果不足够,应该如何改造。甚至软件开发者要关注IO系统应该如何做优化,如通过数据缓存优化IO效率。
对于数据质量,即图像的质量、激光雷达的质量、传感器的时钟,标定是否对齐。如果采集回来的数据达不到这些质量,需要判定这些数据对后续算法到底是否可用。同时,对于数据来说,有一个非常重要的点,要符合法律法规,要使用合规的数据库,采集时也要做数据脱敏,不要有任何法律上的问题。以及在数据回传之后,也要有一些回传入库和入库质检的步骤。数据入库之后,批量数据才能够进行标注。对于标注系统,如果能够全自动化的标注,效率肯定是最高的,另外人工校验也是非常重要的。

那有了数据文件之后,该怎么把它用起来呢?这时还需要很多的数据工具,需要开发各种数据访存SDK,像视觉数据、雷达数据,它们的文件size都是非常大的,在数据的访问、查询、跳转、反序列化过程中,或解码过程中,效率是否足够高。对于数据的统计能力,数据帧率、延迟、关键信号的稳定性,底盘数据是否丢失,数据转码效率是否会很高,是否能够很明确的给这些数据一些label,让下游真正的把数据用起来。
对于数据调试和profile工具,当拿到一个数据时,可以构成各种信号的topic,是否能够很好的关注这些topic的波形图。对于数据来说,是否能够分析实际运行过程中的WCET,进而分析执行时间。由于数据都是在后台运行,所以也需要展示工具,展示图像、感知结果、3D信息、点云。在车内也需要有HMI,如上图右半部分所示,是点云数据和HMI的展示状态。

地平线艾迪平台,能够支撑完整的数据闭环链路。在智能驾驶终端上部署整个地平线的智能驾驶软件,然后通过数据触发、关键场景的问题挖掘,能够把这些经过脱敏之后的原始数据加密传输。之后在云端能够进行端侧的问题挖掘,半自动或者全自动的标注工具进行数据标注,自动化的模型训练,长尾场景的管理,自定义迭代工作流,软件自动集成,自动化回归测试,OTA升级等。最后,再回归到车上,这也是一个软件2.0非常重要的概念。

接下来讲解硬核调度和感知算法部分的内容。
硬核调度如上图所示,今天简单讲解两个部分,首先是Codec。
征程3和征程5提供4K@60fps Codec + 4K@60fps JPEG编码能力。对于Codec,如果只是使用它,不会有什么问题,我们的软件工程师需要看Codec编码到底是做什么用的。对于数据采集来说,Codec要尽可能的调高图像效果。
Codec码率应该如何设置,QP值该如何调整。如果是JPEG,quality配置究竟调成什么质量,才能够满足后续算法的迭代过程。除了给算法进行训练,Codec还有一些DVR数据回传的需求,当带宽不足时,又要权衡究竟设置什么样的码率和图像质量,能够满足数据传输的size要求。
通常Codec在单SoC只有一个加速硬核。但单SoC有6V、10V、11V的系统,虽然Codec能力很强,但Codec也需要一个比较好的调度器。如上图下半部分所示,是一个简单的调度器,它主要是在硬件响应过程中,与硬件交互,让中断更加及时响应到用户层。

更重要的还有模型前处理、后处理以及BPU调度。通常算法开发者更多的是在云端工作,拿到一些标注好的数据,训练模型,并通过地平线的编译器,转换成地平线芯片可以运行的模型文件在BPU上去运行。
对于软件开发者来说,要调度一个模型,和调度CPU不会有本质的差别,那差别是什么呢?是要理解算法的一些数据排布。要理解地平线芯片,在实现计算时这些数据排布到底是如何实现高效率。对于深度学习来说,数据排布通常有vector、matrix和tensor。如果对于软件开发者来说,通常习惯将数据转换为Native Layout(NHWC)。但对于硬件来说,硬件在输出时,数据排布往往也不Native,转换Native Layout往往不是最高效的。这时就要做权衡。Native Layout用户的编程逻辑会比较简单。但不同芯片的原生Layout,性能往往是最优的,所以这对软件开发者的要求也会更高,因为数据不会经常是连续的一个数据块会存在一个区域,另外一个数据块会存在另外一个区域;开发者需要理解硬件原生数据存储格式。
开发者也需要理解定点化的概念。在模型的前处理和后处理过程中,算法往往会做定点化,定点化会让模型的效率运行的更高。对于软件工程师来说,如果不理解这个模型本身数据输出的含义,通常在实现的过程会出现一些代码效率上的问题,即把定点直接转成浮点。在模型计算过程中使用定点计算,而结果解析使用浮点计算,造成了性能上的损失。
这就要求软件工程师理解一些基础算法处理的逻辑。像Bounding box regression究竟是怎么做的,它的原理是什么?NMS是怎么做的?软件实现为什么可以把整个计算过程实现成定点而不是浮点?即便是不同模型,也需要理解摄像头的一些 projection model, distortion model。因为未来更多的是2.5D和3D的算法,模型inference出来后,可能会是不同坐标系下的数据,需要进行坐标系转换。
对于软件工程师来说,如果不理解projection model和distortion model,这些数据很难转换成驾驶系统里面真正上下游需要的一些数据,包括一些Heatmap、Max Pooling如何实现?代码的效率如何才是最高的?一些关键点回归的原理是什么?这些都是对软件工程师提的更高要求。
BPU调度,和SoC中CPU是比较类似的。CPU会有非常多复杂的任务调度。地平线征程芯片拥有双核高性能BPU。如果一个系统中有11路摄像头,通常会面临着50~100个模型的调度。这时整个模型管理、调度编排非常重要;哪些模型是重要的?到底能不能抢占?通过软件方案做一些模型的抢占,还是硬件方案做模型抢占?模型抢占是否会对DDR带宽带来一些冲击?整个体系架构从DDR到SRAM,再到BPU的执行,如何才是最优的?这些都是软件工程师需要关注的一些点。在地平线Bole开发平台发布EasyDNN,它可以帮用户更好的面向复杂的模型调度、调度编排和抢占,解决相关调度上的问题。

在传统的感知方案中都是一些2D的方案,而现代的一些算法方案,不管是3D方案,还是未来的BEV的方案,都需要在模型后期,再增添一些传统的CV算法。在感知模型基础上,进行感知结构化处理。
首先,要有一个自车的位姿估计。位姿估计可以使用车辆底盘积分,对于简单的行车模式下,Speed+yaw rate就足够了。而对于一些低速场景,还需要引入轮脉冲轮速、方向转角等方法。对于每辆车的yaw rate,即横摆角速度,也会存在一些bias。当车辆处于静态时,就会有一个静态偏置,动态时也可能会有一个动态偏置。把 bias估计好才能够得到一个更好的自车里程计。
同时,也可以使用IMU和GPS来提高里程计的精度。上图右上角是一个行车的轨迹图,它有两种颜色,一个蓝色和一个橙色,通过Odom的提高,展示出了两种不同方法的实现结果。
使用IMU,还能够进行3D姿态估计,特别是在跨层辅助泊车的场景。在这个过程中,也会遇到很多工程上的问题,对于CAN数据、底盘数据到SoC系统里,它的链路是比较长的,如何更好的提高系统的响应,保障Odom延迟在一个可接受的范围内,这也是软件工程师需要解决的一些问题。
在动态目标建模方面,要处理的是一些多目标跟踪、运动学的建模,(CV、CA、CTRA等),以及不同的滤波器(EKF、UKF、PF等)。在处理过程中,也需要图像空间与3D空间进行交叉验证。同时,动态目标建模也是一个时间敏感的系统。对于场景的不同,会有一些不确定性。因为传统CV和多目标跟踪,它的耗时是随着目标数量而增长的。而对于深度学习,耗时的确定性是比较高的。对于软件工程师来说,一方面需要用数据工具,profiling整个系统,能够动态的调整数据流,让整个系统尽可能压低负载和延迟。
同时,也要去考虑对于确定性和不确定性,后面应该如何解决它。对于软件2.0的系统,或端到端的系统来说,需要把更多的传统CV部分,转移到深度学习模型或BPU模型,能够被硬件确定性执行的部分,来提高整个系统的确定性、稳定性和延迟优化。
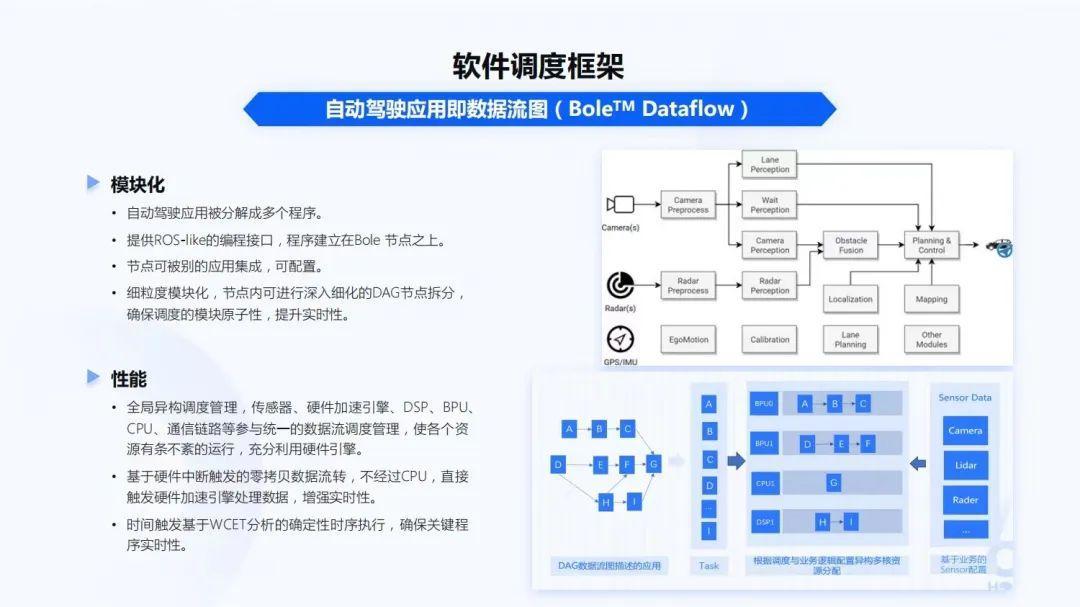
讲到调度,Bole Dataflow调度框架,能够帮助开发者快速构建自动驾驶应用数据流图。整个系统里会有各种的传感器、硬核调度、传统CV的处理模块。各个的模块都会有自己的执行单元,整个自动驾驶应用也被分解成很多的程序。
Bole Dataflow调度框架,也提供ROS-like的编程接口。为什么是ROS-like?因为对于很多自动驾驶算法开发者,特别是学校里的一些同学,他们在学校上学时都是用ROS,所以ROS-like能够让这些算法开发者更容易的在嵌入式上进行开发。程序整个建立在Bole Dataflow的节点之上,节点可以被应用集成、被配置。同时,也会在细粒度的模块化节点内,进行深入细化的DAG节点拆分,确保调度模块的原子性,提升实时性。像上图右下角,就是DAG数据流图描述的应用。
在SoC上,也有很多的硬核,不同的硬核都有不同的计算能力和性能。全局异构调度管理,传感器、硬件加速引擎、DSP、BPU、CPU、通信链路等参与统一的数据流调度管理。只有把所有的调度管理统一起来,才能使各个资源有条不紊的运行,充分利用硬件引擎。这样基于硬件中断触发的零拷贝数据流转,不经过CPU,直接触发硬件加速引擎处理数据,来增强实时性。而时间触发基于WCET分析的确定性时序执行,确保关键程序的实时性。

在多个模块、多个进程,甚至多个SoC的过程中,除了调度,通讯也是非常重要的。Bole Communication通讯框架,支持集成多种消息中间件DDS、ZeroMQ、AutoSAR ARA::COM、PCIe等。关于PCIe,由于未来还有跨SoC、多SoC这种非常大量的数据传输。面向未来的架构,在多SoC时,数据传输通常是在几十兆每帧级的feature map,而传统的以太网肯定不能很好的承载。PCIe在未来会是一个非常重要的数据通讯链路。
Bole也会提供Zero-Copy共享内存通信机制,同时也会内置一些自适应通信策略,来保障节点部署是一个最佳通讯的模式。Bole提供多平台的支持。开发者除了在地平线的芯片上开发,还会在不同设备上进行开发。很多的算法开发者在做算法开发时,不管是调度框架还是通讯框架,在个人的电脑集群上都需要提供编译、调试能力。同时,对于通讯来说,算法在集群上做模型训练,也可以通过Python接口,让算法简单的替换嵌入式模块的一个程序,这样也能够快速的进行算法原型验证。
调度和通讯是大的框架级别,再深入是每一个Node。如果一个Node的运行时间过长,什么样的调度框架和通讯框架都很难进一步的提升性能,所以软件性能优化也是整个软件团队非常重要的一部分,这一块也需要非常深入的了解才能够完成。
做软件的性能优化,需要理解芯片的一些架构设计。首先,需要理解整个Memory Hierarchy,即整个内存的层级系统,也需要理解总线带宽、DDR带宽、DDR控制器到底是如何运作的,还有DDR工作模式。因为现在大算力的SoC,DDR通常是双通道和多通道,DDR到底是运行在并发模式,还是在其他的模式下运行,DDR的QoS到底给哪个硬核才能让它的响应最高,这些都需要考虑到。
对于CPU来说,CPU L2 Cache,L1 Cache工作模式是什么,各级Cache Size对系统性能影响是什么?系统中什么样的数据需要自动去刷新,什么样的数据不需要?对于BPU来说,一个模型有多级的SRAM,它的工作机制、模型调度与IO之间的overhead到底是什么样子的?
对于DSP来说,又会出现一个TCM,TCM和DDR之间使用DMA。对于TCM的使用,到底是使用什么样子代码固化在TCM上,什么样的代码固化到DSP的cache上。
以上这些对整个的系统,整个Memory带宽、软件性能有非常大的影响。
同时,要理解整个芯片设计的Interrupt Hierarchy。当一个系统里有十几个摄像头、几个激光雷达,整个系统的中断是非常多的。我们的软件究竟如何配置中断,中断和CPU之间中断响应是如何绑定的?
也需要在纯计算优化的方式上,深入理解向量化编程。向量化编程一般都称它为SIMD,在ARM上有NEON,在PC上有SSE以及DSP这种SIMD指令,这都是非常重要的软件优化手段。
内存访问需要静态化。因为现在大家开发都在 OS以上,不管是Linux也好,QNX也好,对内存的静态化非常重要。特别是在QNX系统上开发,QNX对内存每次申请释放都会有很多的安全性校验,如果是太多的碎面化内存,整个系统的overhead会非常重。
CPU计算的定点化。定点运算肯定比浮点运算要快,什么样的算法能够定点化,这也是软件工程师和算法工程师需要去深入沟通的。系统里到底哪一部分算法是非常重的overhead,能否把它定点化实现。
对于整个复杂的自动驾驶系统,像11V、3L的系统,它的线程/进程非常多。线程和进程的优先级到底是什么样子?在一个实时系统里面,不同的功能模块的实时优先级配置,线程是否能够合并、绑定。
在系统整个的通讯优化方面,因为系统里面会有各种各样的信号,可能会有非常高的高频信号,也有一些低频信号,哪些信号是可以合并的,哪些高频信号可以做一些打包。例如可以把一些高频信号,比如每个信号都是100赫兹,有几十个信号能否把它们全部打包成一个100赫兹,减少通讯的开销。
更高要求是一些算法复杂度的优化。算法复杂度的优化,通常有可能把一个算法耗时降低一个数量级。
最痛苦的有可能就是纯代码级的优化。因为需要在代码中一个点一个点去check,发现到底有哪些点可以再进一步的优化,能够把系统的性能进一步的提升。特别是量产的最后阶段,有可能花很长的时间都是零点几个点的CPU降低,但这也是非常值得的。
综上所述,在地平线各代的征程芯片上,上面讲到的各种软件相关的开发事项,遇到的各种问题,以及问题的解决,它们在地平线的量产落地的项目中都有体现。
过去地平线已经完成了从0到1的突破,现在也准备和行业伙伴一起实现从1到N的开放共赢。大规模量产是验证智能驾驶产品技术领先性的首要标准,刚刚讲到了很多在量产过程中遇到的问题和解决这些问题的经验。而把这些问题和经验分享出来,也是希望能够帮助大家在后续量产的过程中更好地应对这些问题。
2
软件视角的“软硬结合”与“软硬解耦”

新一代汽车智能芯片领导者,必须也是世界级 AI 算法公司。地平线是在2015年成立,而我是在2016年加入地平线,当时还是处于芯片开发的初期阶段。我个人也非常幸运能够在早期加入地平线,经历芯片软硬结合,协同设计的整个过程。
对于一个软件开发者来说,当你从市面上拿到一款芯片,芯片可能有各个不同的硬件设置,它的DDR、各个硬核的IP,深度学习芯片的一些算子,到底是不是工程上需要的,这些都无法改变。
地平线在每一代芯片的设计、BPU设计、整个SoC的设计过程中,都和我们的软件开发者、算法开发者进行了非常深入的讨论,以软硬结合的方式,让芯片真的是为后续的应用场景、为软件去服务的,即我们的芯片设计,真正的从实际场景出发,从软件中来,到软件中去。
地平线的芯片DDR带宽到底需要多少,BPU算力需要多少,CPU、SP、Codec等,是否真的是一个极具性价比,极具能耗比的设计?是不是能够把AI芯片的能力在自动驾驶的系统里充分展示出来,这个都是在开发过程中软硬结合的体现。
芯片设计出来后,面向芯片,需要在软件层级上,从OS到基础中间件,再到应用中间件,打造不同的模块单元,让不同的开发者使用不同的、已经封装的、比较成熟的模块。像刚才介绍在自动驾驶系统设计中遇到的各种各样问题,这些模块都能很好地解决,并提供给开发者去使用,让开发者能够自定义的完成他们的应用开发。

因而,从芯片到上层的操作系统,基础中间件、应用中间件的软硬结合,再向上提供给我们的应用开发者,去开发各种各样的智能汽车应用,达到软硬解耦。
3
智能驾驶软件开发平台Horizon TogetherOS Bole™
在征程5代芯片发布时,也发布了TogetherOS,Bole是TogetherOS中的应用中间件部分,即软件开发平台。Horizon TogetherOS Bole™是面向高等级自动驾驶的软件开发平台及中间件。
首先,介绍下高等级自动驾驶系统面临的难点与挑战。第一,自动驾驶车载软件的架构复杂度是陡增的。在过去的两三年,L2级别单目的视觉系统比较主流。而从2021年开始,一辆车装载多个摄像头,完成NOA(领航辅助驾驶)等功能,已经逐渐开始是一个标准化的过程。未来到城区自动驾驶,传感器会越来越多,整个自动驾驶的车载软件架构设计,复杂度也是陡增的。在快速迭代过程中,如何能够提高开发效率,实现快速的复制,加速量产开发的进程,都是会变得非常重要。
第二,自动驾驶平台软件关键技术还没有标准化。传统车载应用软件的开发范式,很难做到以数据为中心的数据闭环。整个数据闭环过程中,传统的软件开发方式会显得比较困难。AutoSAR AP、ROS等高等级自动驾驶场景还处在初期摸索阶段。在落地过程中,各有千秋,目前行业中还没有形成统一的面向高等级自动驾驶的软件开发平台及中间件。
第三,高等级自动驾驶也需要更高的安全性保障。关于功能安全部分,此前也有同事有过相关的分享。
最后,高等级自动驾驶也需要高算力的支撑。L3+自动驾驶算法复杂度及功能安全的冗余设计,随着自动驾驶等级的提高,其所需算力呈指数提升,需要BPU/DSP等异构执行单元对算法进行加速。同时,当前单芯片的很难满足算力要求,多个异构芯片混合,软件与计算平台协同也变得越来越困难,自动驾驶计算平台的有效算力很难得到充分发挥。以上这些都是高级自动驾驶系统面临的一些难点和挑战。
总结一下,需要安全可靠、极致效能,简单易用,而且也要面向下一代智能驾驶,是一个能够很好达成软件开发的系统,而且也需要是一个开放且兼容的系统。

Bole,希望能够解决自动驾驶量产软件开发中的难题,面向高等级自动驾驶,完成上图右半部分所示的数据闭环、软件2.0的开发方式,能够做到数据的录制、实际的开发,然后部署。我们将Design、Develop、Deploy、Build、Drive,Measure,Record,Store等等,把它整个闭环起来,和艾迪平台一起,配合着完成数据闭环。

Bole会产出一套面向高等级自动驾驶的开发范式;BoleStudio IDE,能够把不同的模块、不同的node,以DAG的形式展现出来;BoleViewer,能够完成数据可视化;还有一些数据工具,像Recorder、Repaly、SensorCenter;包括车身的一些通讯VehicleIO;也有之前谈到的Bole Dataflow调度框架,通讯框架Communication,BPU调度框架EasyDNN等,它们都是为了能够快速的开发和集成。同时,HobotCV也是面向征程芯片不同的硬核计算单元,提供高效的接口抽象。
数据闭环,也是以数据驱动开发,助力自动驾驶应用快速落地。在实车的环境下,要实时抓取传感器的数据,在实车的应用软件下,能够把传感数据与日志进行录制,包括传感器的标定、常规数据采集。数据回来之后,刚才也提到数据工具也会非常重要。在云端要有数据回灌的能力,特别是在云端和艾迪的配合,对于批量的数据、批量的设备来说,艾迪平台和Bole一起协同,能够把数据的开发、回灌、回归、数据可视化总体整合起来。同时,也提供一个BoleStudio的AI应用开发集成环境,能够做到持续的改进与开发。
4
智能驾驶应用软件开发趋势展望

对于自动驾驶的应用开发,未来会是什么形态呢?
在Bole之上,刚才也谈到会有各种各样不同的模块。在Dataflow框架中也会把各种各样的模块,抽象成不同的一些module,或者node,可能会执行在不同的计算单元上。有多模传感器、摄像头、激光雷达、毫米波雷达、超声波雷达等。感知要在一个大的感知模块下,要执行BPU、传感器,执行传统的CV算法。然后在定位地图上,还要与做地图的一些localization或者自身的定位信息,组成整个动静态环境模型。在融合与规划部分,得到自车的轨迹规划。之后到整车控制,所有的数据可视化,包括整个的车身通讯,各种各样的信号,这些都会是自动驾驶开发系统中需要实现的一些模块。
如果要去做一个自动驾驶系统,从零开始实现这些内容,是非常困难的。如果能够有一个很好的baseline,地平线也是很希望把这样的一个baseline开放出来,能够把我们在量产过程中积累的软件开发经验,以这种module,或以node的形式,和各个合作伙伴一起把它作为一种开发的基础模板,加速合作伙伴的量产过程,这样会是一个更快的开发方式。

基于整个开发框架,会有各种各样不同的模块。上图所示蓝色的部分是地平线所做的开放框架,把在软件框架以及量产工程实现过程中,遇到的一些经验和问题抽象出来,作为一些开放的框架。同时,用户也可以自定义的完成各种不同模块,包括一些新传感器的接入,一些新的传统CV算法的实现,以及不同模型的前处理、后处理,都可以在我们的调度框架下完成。
同时,在整套框架的定义下,也能够把这些感知模块、融合模块、规划模块、控制模块的接口很好的定义抽象出来,帮助开发者快速实现全栈的自动驾驶开发过程。一方面,能够在一个相对比较成熟的软件baseline下,完成自动驾驶量产的开发;另一方面,把我们实现规模化量产过程中的一些经验也分享出来,通过协同开发,大幅提升开发效率,从而达到一个开放共赢的状态,加速智能驾驶应用落地。
我今天的讲解就到这里,谢谢大家。



-

凤凰网汽车公众号
搜索:autoifeng

-

官方微博
@ 凤凰网汽车

-

报价小程序
搜索:风车价


.png)
大家都在看







趣图推荐
.png)