巴菲特不看好的“特斯拉车险”,我认为车企或可大有可为
作为开车一族,你的车险每年多少钱?你用车的频率有多高?
你有没有发现一个问题,就是即使你一年没有开车或者很少开车,你却要和经常开车的人买差不多一样价格的车险,这合理吗?
不合理。那怎么办?
这个问题,容我卖个关子,文章后面回答。

特斯拉将于5月底推出自己的保险产品。马斯克称,特斯拉对一个人“基于汽车”的风险有“直接的了解”,这给予了公司“信息套利的机会”。
不过,巴菲特对此并不赞赏。
据澎湃新闻报道,5月4日,在一年一度的巴菲特旗下伯克希尔·哈撒韦股东大会上,巴菲特表示,埃隆·马斯克的特斯拉可能会因冒险进入保险业务而陷入困境,汽车公司进入保险业务可能与保险公司进入汽车业务的成功率差不多。
巴菲特从投资角度分析这件事,作为订阅咱们“刘润”公众号的朋友可能了解,咱们号的特点是洞察事物本质。
那么,我们就从这个角度来分析下:
为什么特斯拉会推出车险?车险、乃至保险的本质又是什么?
— 1 —
你有没有想过这个问题?
为了说明这个问题,我们可能就要从最初的保险,甚至保险的本质说起:
保险的本质到底是什么?
我想用“份子钱”的例子帮助你理解。
比如在一个村子里,一个人再穷,也要娶媳妇吧,不说置办新房等事情,最起码也要摆个酒席,请全村人喝喜酒。
可是没钱,那怎么办?
村里是这样解决的,一旦有一家办喜事,每家人都会包红包,这样钱就够了。过段时间,其他村民家里有人结婚,也没钱,全村的每家人也会给他包红包。
为什么要这样解决?不能每家自己攒钱娶媳妇吗?
不知道你有没有注意到,包红包、随份子的这种事情有两种属性,第一种属性是它发生的概率特别小,一辈子通常只结一次婚。另一种属性是,这种概率很小的事情一旦发生,花费却特别特别大。
符合这两种属性的事情,民间自发形成了一种逻辑,一群人把它平摊掉,因为每家每户几乎都要娶妻生子。
这其实就是最原始的保险,它的本质是同质风险分担。
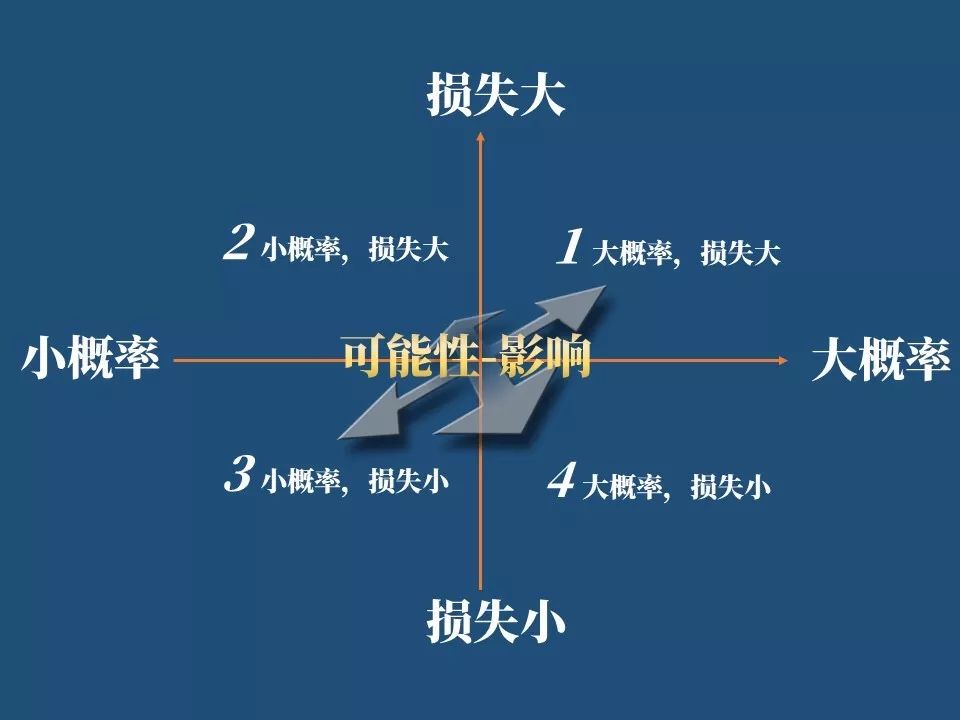
我们通过二维四象限图能更好理解,横轴是可能性,纵轴是影响。
可能性很小,但是一旦发生影响特别大,也就是损失特别大的事情,位于第二象限,在这个领域的事情,我们通常选择平摊风险的方式来解决,婚礼就是属于这样的场景。
我们甚至开玩笑可以给随份子、包红包起个保险术语,叫“婚礼险”。
— 2 —
理解了保险的本质后,我们再来说车险的本质。
比如说100万辆车,有一辆会出车祸,比如一旦出车祸赔100万,这就意味着100万人,如果我们每人出点钱,凑足了100万,这事就解决了。
那100万人出100万,每人就出一块钱,那么这个时候真的出事儿的那个人,100万也不用自己出了,每人一块钱也不觉得多,这就是车险。
那现实世界中,我们是怎么操作的呢?
我们是通过一个中心化的机构也就是保险公司购买这份车险,价格是保险公司基于社会统计数据,然后做精算后得出的。
但是这么做,其实不科学。
为什么不科学?
这100万辆车出险的概率是不一样的,这是关键。
就比如开头的问题,凭什么不经常跑的车和经常跑的车车险价格差不多?凭什么遵守交通规则、开车习惯很好的人和经常疲劳驾驶、猛踩刹车的车险价格也差不多?
凭什么?
因为,我们现在的车险是基于社会统计数据所产生的,它不是个性统计数据,这就造成一个问题,违反了保险本质。
我们上文提到保险本质叫做同质风险分担。
什么叫同质风险?
同一个村子里的村民,村民们都认为自己家的孩子总归会结婚,所以大家可以互相包红包。
但基于社会统计数据的车险却不是基于同质风险的。

你是一个开车不多、开车习惯很好的人,却要和天天开车,跑很多路,开车习惯还很糟糕的人一起在同一个池子里分担风险,那你就吃亏了。
所以基于社会统计数据,它产生的保险不是保险的最终解决方案。基于社会统计数据的保险,只做到了风险分担,没有基于同质。
— 3 —
特斯拉将要推出的保险能做到同质吗?它可能会做什么?
可能就是通过大数据,也就是更多的个性化数据,比如你的行车习惯、踩刹车油门频率等等这些数据。
基于这些个性化数据就能把同质这个问题解决了,就能让风险指数一样的人在同一个池子里购买保险。
如果,这样说你还不能理解,我们来举个例子。
——
美国一家保险公司State Farm,它是怎么基于UBI模式设置保费的呢?State Farm 根据汽车内置TSP或OBD设备获取数据,然后主要看三个数据。
第一,看你跟前车的距离。
第二,看你每天猛踩刹车的次数。
第三,看你有多少次是凌晨四点钟在开车。
通过这三个数据,它就能判定你出险的概率是大还是小,突然间踩刹车就说明这习惯太不好;与前车距离近表示你出险的风险大;凌晨四点还用车,说明很可能疲劳驾驶。
它就用这个东西来定价,价格就可以比其它基于社会统计数据的保险定的便宜。
这个本质也不是价格比别家保险公司便宜,而是它能把那些出险几率很低的人给找出来,这对这些出险几率低的消费者来说,交的保费就比以前便宜很多。
这样也就做到了同质风险分担,但这需要一个大前提,那就是你要掌握每个人的个性化数据。
怎么才能掌握个性化数据?
那就像State Farm一样,给每辆车安装一个新设备。
但这也会产生一个问题,那就是安装这个设备的成本比较高,因为你要说服消费者,让消费者安装一个车里本来没有的设备总归需要一些解释、说服工作。
但对车企来说,就不一样了。
车企完全可以在车出厂的时候就安装好,在经过消费者授权的情况下,就可以记录这些数据。
这时,这些类似特斯拉这样的车企相对于只会基于社会统计数据做风险分担,但是不会同质的保险公司,就有一个巨大优势。
所以,我认为在车险这个领域,汽车企业大有可为。
— 4 —
据银保监会数据显示,截至2018年上半年,车险保费在财产险中占比约为70%。
这是一块很大的市场,而现在国内的车险仍然是基于社会统计数据做风险分担,一旦有特斯拉或者其他车企基于个性化大数据推出同质风险分担的车险,那会发生什么情况呢?
我们举个例子:
比如,你买了一辆车,第一年可能买了6000元车险,如果第一年你的驾驶习惯很好或者开车的频率也不高,第二年,掌握你驾驶个性化数据的车企跟你说,只要3000块,就能在它那购买车险。
你是不是就会买3000块这个保险了。
那你买3000块这个基于你个性化数据的保险本质是什么?
本质是你不用在基于社会统计数据这个分担池子里分担风险,而是进入另外一个出险系数更低的池子里分担风险了。
在这个池子里,同样100万人,因为出险系数更低,你分担的风险就会小得多,所以购买的车险金额也会少很多。
这时像你这样,越来越多的人购买基于同质风险分担的保险,那些基于社会统计数据做风险分担的公司就会发现,为什么我的客户出险率越来越高了?
那是因为那些出险系数低的优质客户都离开了,剩下的都是那些出险系数很高的人。
为什么出险系数很高的人会留下来?
因为这些人如果购买基于个性化数据的同质风险分担车险,价格会更高,第一年是6000,很可能第二年就要8000,甚至10000。
所以,这些基于社会统计数据的第三方保险公司,未来很有可能只能做那些性价比很差的生意。
— 5 —
一切事物背后,都有其商业本质。
回到最开始的话题:凭什么很少开车、驾驶习惯好的你要和天天开车、驾驶习惯很糟糕的人买一样的车险?
相信读完今天的文章,你一定了解其本质是因为现在的车险是基于社会统计数据分担风险。
解决这个问题,一定就要回归到保险的本质,那就是同质风险分担。
而为了实现找到“同质”的客户,保险公司额外装一个采集数据的设备要比车企在出厂时预装“说服”成本高很多,车企在这方面效率更高。
所以不仅特斯拉,将来各大车企,比如通用、大众、奔驰等等大型车企都有可能会推出自己的车险服务。
因为,商业的方向只有一个,那就是提高效率。
最后的最后,如果你作为一位车主,你是否期待这种“同质风险分担”的车险呢?
如果你是一名汽车行业从业者,你的企业是否有推出车险的计划呢?
如果你是一名保险从业者,你是否认为将来车企将会对你的业务构成挑战呢?
欢迎在留言区说给我听,我们一起讨论。



-

凤凰网汽车公众号
搜索:autoifeng

-

官方微博
@ 凤凰网汽车

-

报价小程序
搜索:风车价


.png)
大家都在看







趣图推荐
.png)