特斯拉AI Day 前瞻,马斯克疯狂招人为哪般?
不久前,马斯克通过个人推特,正式公布AI Day将在8月19号举办。
这场“预热”了大半年,还鸽了一个月的技术日,被马斯克定义为了“AI人才招聘会”。实际上,早在6月份的CVPR 2021上,特斯拉AI主管Andrej在演讲中,也频繁地暗示,希望有“智”青年加入特斯拉的AI团队。

利用每个公开机会在线“摇人”,特斯拉似乎在这样的时间点发生了“用工荒”。通过公开信息来看,特斯拉近期并未出现大规模的人才流失。
如此迫切招人,真相只有一个,特斯拉智能驾驶研发上迈入了新的发展阶段,也遇到了整个行业此前都没有遇到的难题。
特斯拉的算法模型领先了多少?
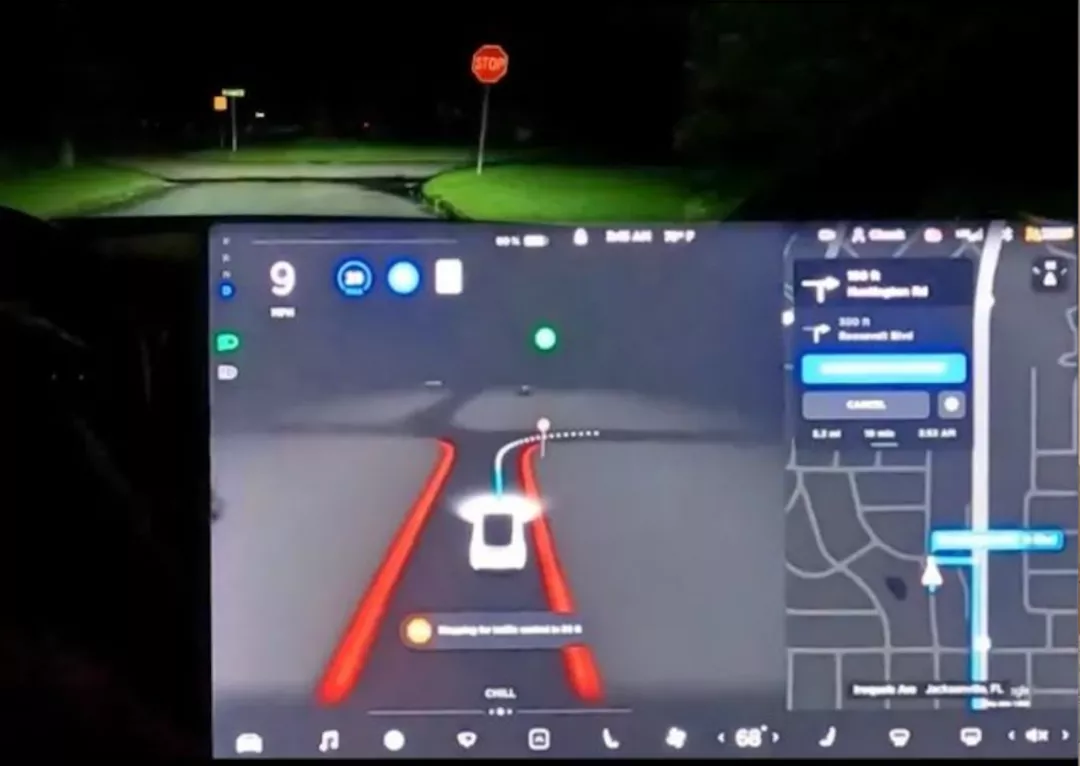
特斯拉今年7月在北美推送了 FSD Beta V9,通过国外网友的热情分享,国内用户也“云”体验了V9的实际上路表现。V9基于纯视觉,能实现点到点的自动驾驶辅助,可以自主处理城市道路中复杂的人车混流、无保护左转等场景。
虽然V9的表现还不尽人意,甚至有国外权威人士吐槽这个版本的FSD,“如同一个喝醉的人在开车”,但至少从系统推出的时间来看,特斯拉是暂时领先的。
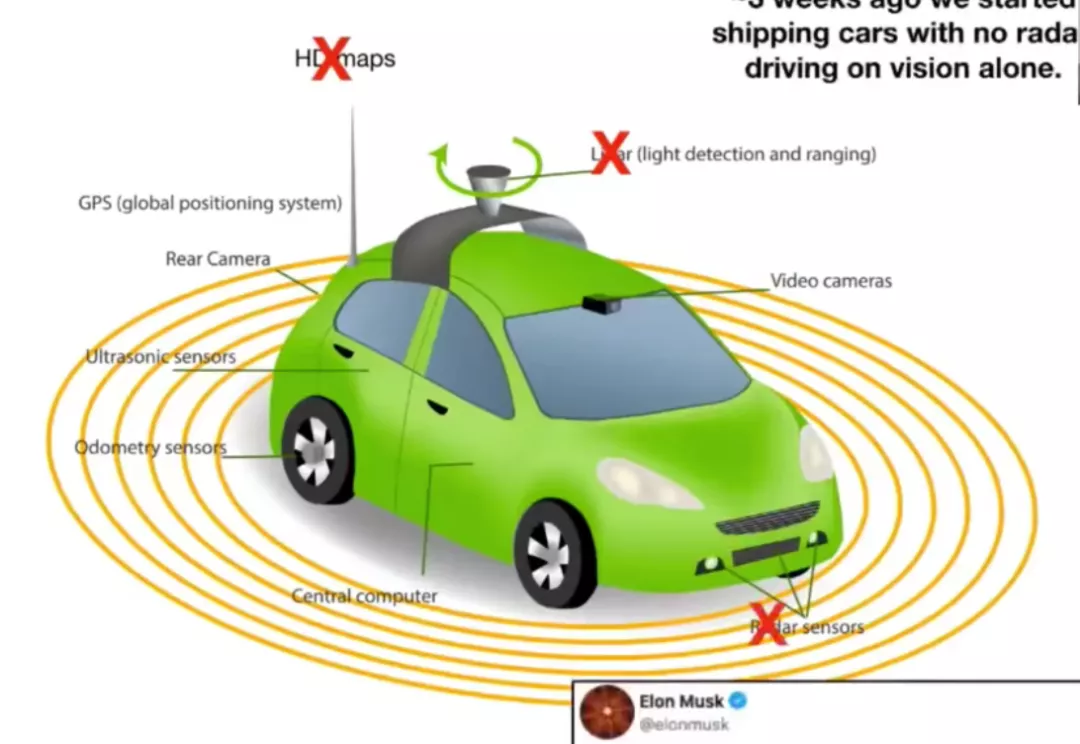
消费者视角来看,特斯拉的领先,主要在于算法模型的领先带来的功能领先。特斯拉通过纯视觉就能理解环境的深度信息,能够预判目标的行动轨迹,不需要高精地图就能实现微观的路径规划,这些都使得V9能够仅依靠摄像头的感知,就能实现全场景的辅助驾驶。
部分业内人士并不这么认为。“从算法模型设计模型结构优化方面,我觉得大家基本都拉平了,最大的差距就是在它的数据量上面”,商汤科技高级项目经理赵蒜告诉Dante Tech。
纽迈科技计算机视觉研发总监成二康也告诉Dante Tech,计算机视觉发展到今天,单纯算法模型层面,基本已经不存在谁绝对的领先,整个计算机视觉发展是比较开放的,前沿的研究也是开源的,想要在开放的环境中做到一家领先,几乎是不可能的。
计算机视觉领域有CVPR、ICCV、ECCV这样的顶会,国内如商汤科技、百度Apollo这些关注计算机视觉研究的企业,每年都会有大量的论文投稿。特斯拉也会参与这些计算机视觉顶会,今年的CVPR上,特斯拉AI主管就分享了特斯拉的最新研发进展。

人类在计算机视觉领域的智慧结晶,如同放在一个池子中共享,特斯拉的很多算法模型,也是来自这个池子中的前沿研究。
既然计算机视觉有开放的社区,为何只有特斯拉使用了诸如深度预测、时间预测来识别被遮挡障碍物,SLAM构建局部地图。亦或者说,如果算法模型层面,特斯拉并不比其他车企领先,那特斯拉在功能上的领先地位又是如何奠定的呢?
数据催生的“天眼玩家”
“鱼塘”那么大,特斯拉怎么知道该钓哪条?因为特斯拉是“天眼玩家”,让特斯拉成为天眼玩家的,正是特斯拉的车主们。
CVPR 2021上,特斯拉AI主管Andrej演讲中提到,特斯拉目前已经采集到了100万个10秒视频片段(8摄像头36帧),这些片段中包含了60亿个含深度信息的标注目标,总数据量达到了1.5PB。
1.5PB数据是什么概念呢?1.5PB是1536TB,也就是需要1536个1T的移动硬盘才能装得下,如果换算成高清的电影,大概是50000部,一个人不吃不喝9年才能全部看完。
自动驾驶行业普遍说“掌握场景是获胜的关键”,而场景则是从数据中提炼而来,而想要提炼数据,则需要做好两件事:在架构上能收集尽可能多的数据,在技术上能处理尽可能多的数据。做到了这些,才能成为“天眼玩家”,知道哪些场景存在哪些需求,哪些需求可以用哪些算法模型来实现。

特斯拉收集数据的优势在于,从自动驾驶的软硬件研发,到整车的生产销售,都是特斯拉自己完成的。特斯拉可以通过每辆行驶在路上车,收集并回传想要的数据,用这些数据来训练算法模型,再通过影子模式验证训练好的算法模型。
特斯拉目前全球保有量已经超过100万辆,但私家车在数据采集上,和车企自己的工程车是不同的。工程车可以装配昂贵的存储设备,然后再直接从车上提取出来,这样便可以做到实时的数据存储。私家车无法做到数据实时存储,而出于流量成本考虑,特斯拉也无法在车上做数据的实时上传。
自动驾驶企业AutoX创始人肖教授曾表示,特斯拉的存储硬盘非常小,网络带宽也不大,数据都是现场采集现场扔掉。但如果参考特斯拉AI主管Andrej在CVPR 2021上的介绍,肖教授似乎只说对了前面的一半。
Andrej介绍,特斯拉向用户推送的版本中包含了 Triggers(暂译作:特征触发器),也就是说,每辆行驶在路上的特斯拉,并不会实时上传所有数据,而是设置了一个AI触发算法,通过算法判断是否是想要的场景,并将触发后采集的视频片段上传到特斯拉的服务器中。这些通过Triggers收集的数据已经在车端按照模型训练的需求,通过自监督学习做了标注。

特斯拉是从V9开始公布Triggers了,但实际上从前几个版本,特斯拉已经开始这么做了。特斯拉目前共推送过221 个Triggers,覆盖了不同场景的不同数据采集需求。
业内人士告诉Dante Tech,特斯拉会随着自己的版本迭代,向用户推送不同的Triggers,回传的数据类型也是不一样的。该业内人士感叹到,“我觉得没有哪家企业,能像特斯拉一样,已经把corner case收集到这样一个程度了”。
在车端做数据的打标签并回传,技术难度是很大的,这也就意味着,Triggers的做法虽然听起来很美妙,但实际上采集到“称心如意”数据的概率并不高。特斯拉会收到大量的数据,而这些数据中仅有一小部分是有价值的。
如何提升挖掘corner case的效率,以及如何更高效处理采集的海量数据,成了特斯拉需要攀登的下座高峰。
下座高峰:从技术落地到生产力革命
Dojo超算中心是特斯拉AI Day的重头戏,而Dojo的出现,或许是为了解决Triggers精度低,以及数据庞大带来的新难题。那超算是如何提升Triggers精度的呢?
举个例子,假如特斯拉现在遇到的一个corner case,是无法识别一种特殊的标识牌,这种广告牌在北美有300个,分布在不同的城市。特斯拉向车主推送了采集这种广告牌的Triggers,希望采集完这300块标识牌,用来训练自己的算法模型。
一开始的Triggers并不准确,后台收到20000份数据中,仅有1份是目标广告牌。特斯拉通过超算中心,使用超大模型来处理这些数据,超大模型的好处是,即便是数据量较少,也能保障输出的效果好。简单理解这如同一个你来描述我来猜的游戏,给到的描述越多,猜中的几率概率越高,超大模型的参数量更多,如同描述越多,更能细化出目标标识牌牌的特征。
通过大模型,可以优化Triggers,优化后的Triggers再部署到车上,可能返回的数据就成了1000份数据中有一份是目标标识牌,循环几轮,就能实现收集到全部300个标识牌的目标,而这个corner case也将彻底被消灭。

超算中心除了能提升数据采集的效率,加速消灭corner case,还可以通过超大模型提升AI算法模型训练的效率。超大模型可以吸收更大的数据量,输入更多的参数,表现出数据的更多特征,拥有更强的泛化能力。基于超大模型,可以训练出搭载在车端的小模型,通过超大模型训练出来的AI模型,性能会优于普通AI模型。
不光是特斯拉,近年来诸多科技公司都致力于开发超大模型,例如商汤的“AI大装置”,华为的盘古大模型,Open AI的GPT-3模型等。大模型已经越来越被科技公司看做是,需要布局的核心生产力工具。通过大模型,可以降低应用端小模型的开发效率,也能提升应用端小模型的性能。
但大模型除了需要大量数据之外,还必须借助超算中心才能完成。超大模型体量很大,它的计算同时需要在很多块显卡上并行处理,调用整个超算中心的计算能力。
“现在为什么只有特斯拉一家车企建超算,因为它走到了这一步,数据量太大了,需要更好的方式来利用这些数据,但是国内任何一个车企暂时都还用不到,因为它没有特斯拉这么大量的数据处理需求。”业内人士如此告诉Dante Tech。
处理庞大的数据,是特斯拉跨过收集数据和模型架构设计之后,摆在面前的新难题。而除了Dojo和超大模型之外,特斯拉还将面临软件开发层面的生产力工具革新难题。
随着数据变得庞大,如何从海量数据中分拣出有效数据,分拣数据之后如何自标注,标注的数据如何协同开发共同完成模型训练,以及完成模型训练之后,如何快速部署上车,这些都需要生产力工具的革新。因为技术的飞轮已经转动起来,特斯拉必须装上齿比更合适的齿轮,才能确保每个环节都能稳定运转。
随着特斯拉“车队”规模逐渐庞大,依靠Triggers挖掘的数据会呈指数级增长,这如同一条流水线,上游的输入逐步爆发,下游必须要有匹配的生产力工具升级,才能确保整条产线稳定产出。因此Dante Tech猜测,特斯拉这个时间节点迫切招人,大概是应对Dojo及软件生产力工具优化的人才需求。
而数据过大带来的新压力,对其他车企而言,或许是“甜蜜的烦恼”。
特斯拉的“中国劫”
对于特斯拉V9,消费者更关心的问题是,什么时候能够在国内推送。但对特斯拉而言,可能更关心的是,V9到底还能不能在中国推送。
网络安全审查,已经成为影响国内自动驾驶产业发展的重要事件。从滴滴目前的处境来看,从严的概率会更大。
目前涉及到影像信息及定位信息的回传的辅助驾驶系统,只有特斯拉一家。虽然特斯拉也已经在国内建立了数据存储中心,但这只是合规的第一步,从网络安全角度来看,特斯拉需要解决的问题还非常多。

一位接近有关部门的消息人士向Dante Tech透露,特斯拉的数据是实时采集的,路过军区、政府等机要区域时,并没有一个自动关闭的策略,这在中国本身就是不合规的。
虽然特斯拉不依靠激光雷达,不使用高精地图和高精定位,但视觉信息的回传,以及用户驾驶信息的使用,在当下同样是很敏感的。国内的车企,对于视觉信息的回传普遍很谨慎,都在等相关政策的落地,而这也是国内多数车企无法拥有如特斯拉一样庞大数据量的原因。



-

凤凰网汽车公众号
搜索:autoifeng

-

官方微博
@ 凤凰网汽车

-

报价小程序
搜索:风车价


.png)
大家都在看







趣图推荐
.png)