“自动驾驶”汽车是怎么样看路的?
你能分辨照片上是不是有只猫吗?即便三岁小孩这都不是啥问题(照片特别离谱的除外)。
可你能教会一台机器辨认一只猫吗?好像有点难度,我们得先告诉机器啥是猫。机器和人的思维毕竟不太一样,我们教小朋友认猫,只要告诉他那个喵喵叫的就是猫,他很快就能记住,并且能举一反三,但这个方法显然不适合人机器学习。而现在就有一大群人正在做类似的事,其中一批就是教自动驾驶汽车认路的工程师。

01
摄像头为何能坐稳自动驾驶感知的头把交椅
近几年来,高阶辅助驾驶甚至自动驾驶的概念越来越被频繁的提及,而自动辅助驾驶技术也在快速的发展。我们平时开车需要用眼睛观察路况,而自动(辅助)驾驶便是通过感知硬件来感知周围的路况。目前汽车上应用到的感知硬件包括但不限于:摄像头、毫米波雷达、超声波雷达、激光雷达以及V2X相关硬件等。
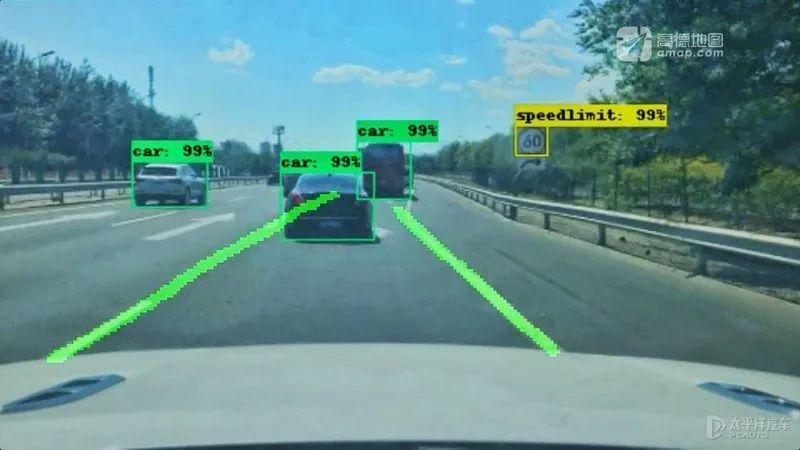
对于自动驾驶感知,纯视觉路线与多传感器融合路线之争由来已久,融合路线中激光雷可以精准的还原周遭环境的三维特征;毫米波雷达对恶劣天气有着更强的适应性,且能够同时探测被测物体的距离与速度;高精度地图能够让车辆提前对沿途道路有更精确的了解;V2X能够借助旁人获知视野之外的情况……

但不论哪种路线,都不会把摄像头排除在外。摄像头是目前最主流的自动驾驶感知硬件,类似人眼看世界,系统算法会自动分析图像并找出其中的各种事物。双目摄像头还可以像人眼一样通过夹角分析出前方障碍物的距离。即便视觉感知也有自己的弱点,其十分依赖算法,而算法需要海量的数据进行训练,对于后来者有极高的门槛。此外,摄像头受逆光、能见度等环境因素影响颇大,识别准确率在不同环境下会有较大波动。

因为自动驾驶汽车,也终究是要在为人类设计的交通体系之中。而人类的感知环境,凭借的就是眼睛的成像,摄像头刚好就是为了还原人眼看到的世界而设计的,因此要让自动驾驶汽车看到人类驾驶员在路上看到的所有信息(包括颜色、文字、标线等),摄像头自然是不可或缺的。所谓纯视觉路线与多传感器融合路线之争,争论的焦点其实只是“只有摄像头够不够”的问题。
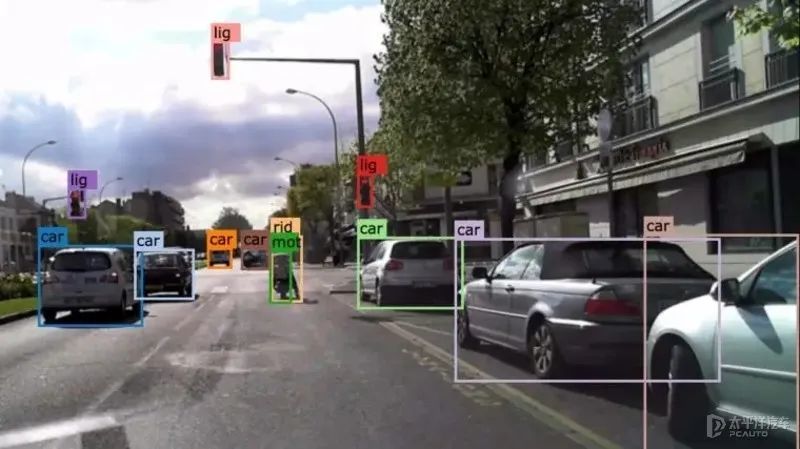
奠定摄像头在自动驾驶感知系统中坚实地位的,除了前面提到的可以获取与人眼一样多的信息外,还有很重要的一点,人类自己能看到的东西,才能更有效的“教”给机器。自动驾驶近年来的飞速进步,依赖的是人工智能技术近年来取得的突破性发展。而人工智能近年来应用进展最为迅速的领域,一个是语音识别,一个是图像识别,刚好对应人类的“听”和“看”的能力。下面我们就从人工智能的发展史,聊聊自动驾驶视觉感知背后的算法。
02
人工智能的两轮高潮和低谷
我们还是先说猫,想教机器认识猫,可以把猫的一些特征告诉机器,比如橘猫是橘色的。后果可想而知,橘子、抱枕、金毛,甚至一些不可描述的东西都可能会被误认为是猫。显然颜色并不靠谱,那我们再加一些特征,比如猫有尖尖的耳朵、一对黑眼睛、四条腿、长长的胡须等等。终于,机器认识了一只橘猫。

可一不小心,老虎、狮子、兔狲等等也都被认成了猫。而一些角度非常规的猫的照片,又莫名其妙被开除了猫籍。很显然,我们输入的条件太过笼统又不够细致。那是不是只要输入足够多、足够细的条件,机器就能认识所有的猫了?很长一段时间,人工智能专家也是这么认为的。

二十世纪五十年代中期,人工智能诞生之初,部分学者便创造了“规则式”人工智能,后来定名为“专家系统”(expert systems)。他们用定制的逻辑规则来教计算机怎么思考,专家系统很快让计算机在跳棋等游戏中击败了人类高手,甚至直接摸到了这类游戏的天花板。

可近二十年的发展高潮,人工智能都没有什么能落地的应用,让人工智能在七十年代中期陷入第一次寒冬。直到1980年卡耐基梅隆大学发明的软件XCON投入使用,这个帮助顾客自动选配计算机配件的软件程序,包含了设定好的超过2500条规则,在后续几年处理了超过80000条订单,准确度超过95%,每年节省超过2500万美元,XCON和同时期的其他实用专家系统,揭开了人工智能的第二次高潮。

随着人工智能的热度攀升,自动驾驶相关的项目也纷纷上马。不过大家最熟悉的,要数这一时期拍摄的美剧《霹雳游侠》里,那台神奇的智能汽车KITT。剧中,KITT有一块每秒运算可达10亿次的CPU和5000兆字节容量的数据库,不仅能够自动驾驶,还能进行人机对话等等。不过事实上,剧中畅想的CPU和数据库水平,甚至不如一台iPhone4。

随着摸索的深入,专家系统的局限愈发凸显。彼时研发语音识别的团队,花费大量金钱聘请很多的语言学专家,参与规则的制定,可惜语音识别的准确率,始终也只能徘徊在60%左右。人类不可能穷尽所有规则的可能性,彼时计算机硬件水平也制约着人工智能的进步。
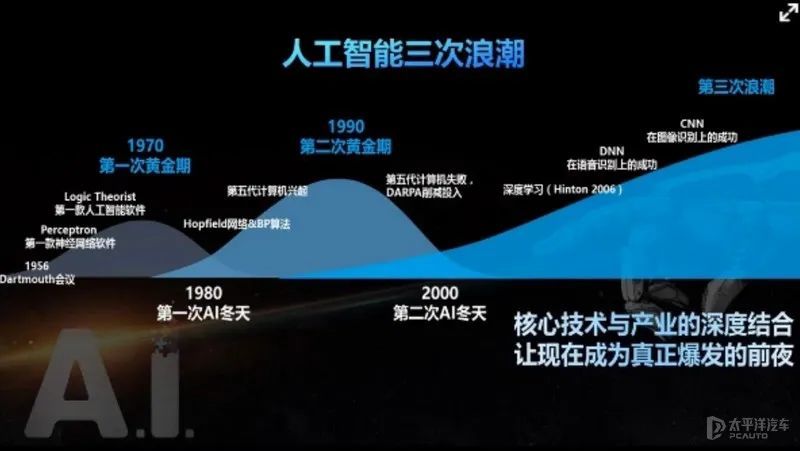
历史的时钟还没能进入九十年代,人工智能在互联网、计算机的发展热潮中,黯然陷入了第二次寒冬。
03
人工智能的第三次高潮和神经网络
1997年,国际象棋世界冠军卡斯帕罗夫面对去年的手下败将,IBM开发的人工智能“深蓝”时,显得并不从容。被当时媒体称为“人类智力的最后一道防线”的国际象棋,以卡斯帕罗夫的落败宣告失守。

这一事件引发了社会热议,人工智能也从此时开始了缓慢的回温。当然,各路媒体很快反应了过来,“人类智力的最后一道防线”又被放在了横在人工智能面前的最后一种棋类游戏——围棋。
让人工智能在围棋上战胜人类,这是个横在”专家系统“的天花板之上的挑战。不是因为无法穷尽的规则,而是太多的可能性远超出计算机的算力极限。答案我们今天都知道了,2016年,谷歌开发的人工智能AlphaGo战胜围棋世界冠军李世石,之后又接连挫败柯洁等围棋世界冠军,彻底宣告了人工智能的胜利。

不过,AlphaGo其实早已不再是专家系统,而是如今炙手可热的神经网络和深度学习。
神经网络的诞生并不比专家系统更晚,同样在人工智能诞生的五十年代,模仿人类大脑通过计算机搭建神经网络,让机器能够自主学习就已经被提出。不过在此后的半个多世纪,没有足够强大的硬件和充足的数据库,基于神经网络的人工智能虽然从未中断,却鲜有建树。

七八十年代,正是IBM最辉煌的一段时期,IBM内部有一大批人工智能相关的项目在推进。其中Jelinek领导了一直很不起眼的小团队,单独开发了一套基于统计概率的语音识别系统,这与当时大量聘请语言学专家的专家系统背道而驰。有趣的是,并不是这个团队有多么高明的远见。Jelinek领导的团队只是IBM内部一直不是特别起眼的小团队,在专家系统火热的当时,这个团队小到甚至请不起想要的语言学专家。
阴差阳错的,他们开发的系统识别准确率,甚至超过了不少专家系统。这个系统框架对至今的语音和语言处理都有着深远的影响,可惜要等到二十多年后这个发明才得到广泛的应用。2006年,Hinton在卷积神经网络领域取得了新的突破,人工智能才终于在此后几年间迎来了第三次高潮。

当然除了个人的成果,时代的发展才是促使人工智能高潮的更大原因。2010年前后,芯片算力已经发展到上世纪无法比拟的高度。1982年拍摄《霹雳游侠》时,对智能汽车KITT那每秒运算可达10亿次的CPU和5000兆字节容量的数据库已经是人们想象中无敌的存在,如今连最普通的入门智能手机都已经超越了其性能,更别说今天智能汽车需要的硬件水平了。
同时移动互联网带来的社交媒体热潮,无意间在互联网上累积了海量的数据。网络上海量的经过标记的数据,给深度学习的发展带来了优渥的环境。

如今基于卷积神经网络设计的人工智能程序,人类不再干预计算机的思考,而是“喂”给计算机大量的数据,让计算机自己去学习、分析。此时计算机不是被人的思维左右,而是形成计算机独立的认知概念。

我们再回到开头的“猫”的问题,社交平台上无数的“猫奴”,每天上传巨量的猫主子图片。把这些带有猫标记的图片处理后统统“喂”给人工智能系统,人工智能便能够轻松的判断,图片里是不是有一只猫。只是就算开发他的工程师,也并不完全清楚,她到底掌握了哪些具体特征进行的识别。
这样的人工智能其实并不具备类似人类的“意识”,现在发展的人工智能短期内也无需担心机器“觉醒”的问题。仅仅是基于大量的数据总结归纳,形成机器独有的一套逻辑。“喂”给机器的数据要多,但也不能过量,超量的数据可能会让系统过拟合,反而影响了性能。
04
自动驾驶汽车是怎么学会看路的?
说了这么多,还没有回到最初的问题,自动驾驶汽车是如何认路的?
很显然,如今的自动驾驶汽车也是基于卷积神经网络开发的人工智能系统,包含了感知-决策-规划-控制等,其中首要的便是感知,也就是我们说的看路。自动驾驶需要看到并认识前方的道路和路上的潜在障碍物才能够执行后续的操作。

训练负责自动驾驶的算法,同样需要海量的相关数据作为支撑。我们之前多次讨论过关于自动驾驶纯视觉路线和多传感器融合路线的优劣,不过对于算法的训练,照片和视频显然是最为易得也最容易进行标记的数据。大家可以想象一下对激光雷达甚至毫米波雷达这种并非人类正常感知的数据进行标记有多复杂。这也是为什么,即便是多传感器融合路线,摄像头依旧是感知硬件中的YYDS了。

在我们普通人的认知中,人工智能必然是十分高科技的一个行业。其中一部分工种当然是,但这也是一个劳动密集型的产业。“喂”给自动驾驶算法的数据并非随便从网上批量下载就可以,需要有大量的测试人员进行专业的数据采集,还需要有海量的标注员对图片进行标记,对照片中的行人、路障等等障碍物进行标记,之后才能够“喂”给算法进行深度学习。
这样的模式不仅吃力,并且精度缓慢。于是人们又想到了让机器对机器进行训练,被称为“无监督学习算法”。在获得一定数量的数据后,机器就可以完成对常规数据的自行标记,再用机器标记的数据训练更多的人工智能算法,这也帮助了如今人工智能的飞速进步。

而人们不得不面对的另一个难题是自动驾驶的“长尾效应”,自动驾驶日常训练中获得的大量数据已经解决了日常常见的绝大多数头部场景中的潜在风险,但那些不受重视的突发场景极为罕见,但种类繁多,日常中很难采集到足够的数据样本对自动驾驶进行训练,但因此累计的总量也已经对自动驾驶的安全性构成了很大的威胁。

以特斯拉为例,在2021年“AI DAY”上,特斯拉介绍了一些罕见场景,例如一起前方卡车卷起的风雪遮挡前方车辆的极端案例。为了解决这一现实中并不多见,但发生时会异常危险的事件,特斯拉利用超级计算机模拟更多的类似场景多神经网络进行了大量训练。特斯拉日常解决的这类“长尾”场景远不是个例。马斯克介绍说,他们会模拟各种能想到的罕见案例,甚至包括了“城市道路出现悠哉散步的麋鹿”,乃至“飞碟坠落”这种完全不可能发生的奇特危险。

但另一个难题是如何发现这类罕见场景,特斯拉在AI DAY上透露,特斯拉搜集在Autopilot驾驶时,驾驶员突然介入改为人工驾驶的场景,这类场景普遍是自动驾驶目前尚不能完全解决意外情况。特斯拉会利用超级计算机分析这个视频案例,找出驾驶员中断Autopilot的原因。又或者司机在高速路上突然刹车、堵车时有人插队、雷达与摄像头判断结果不一致、车辆发生事故/险些发生事故等等,将这些具体的案例,交给超级计算机来分析处理,然后重复前文提到的模拟同类场景训练。
05
结语
从二十世纪五十年代人工智能概念被提出,历经七十余年,经历了三起两落的发展,人工智能终于取得了长足的进步。自动驾驶是人工智能应用的热门场景之一。当然人工智能目前尚不完善,自动驾驶也难免遭遇一些尴尬,但其实现方式决定了这就是一条需要不断积累、试错的历程。科技从来不是一蹴而就的,也就是在这些尴尬的失误帮助下,才能不断成长。



-

凤凰网汽车公众号
搜索:autoifeng

-

官方微博
@ 凤凰网汽车

-

报价小程序
搜索:风车价


.png)
大家都在看







趣图推荐
.png)