黑芝麻智能仲鸣:激光雷达感知算法在A1000芯片上的部署 | 公开课实录

9月20日晚7点,黑芝麻智能自动驾驶技术公开课第一期在智东西公开课顺利完结直播。公开课由黑芝麻智能系统架构高级经理仲鸣主讲,主题为《激光雷达感知算法在黑芝麻智能A1000芯片上的部署》。
本文是此次公开课主讲环节的实录整理。

大家好,我是仲鸣,来自黑芝麻智能,负责系统架构。今天给大家带来的是《激光雷达感知算法在黑芝麻智能A1000芯片上的部署》。
现在,不管是L2.5、L2.9、L3,越来越多的高端智能驾驶车上会配备激光雷达。不管是前向、补盲、4D成像雷达、毫米波成像雷达,这些雷达返回的都是点云形态的数据。这些点云数据的感知算法,也是目前大家在钻研的,希望能够部署到嵌入式芯片上。所以,今天给大家介绍一下,在黑芝麻智能华山®二号A1000自动驾驶计算芯片上如何去实现感知算法。
内容大纲会分成三段:

第一段是有关主流激光雷达感知算法比较。这个可能是相对比较入门、比较基础的介绍,帮助大家更快地理解激光雷达感知算法大概的算法结构,以及这些算法的特点。
第二段会给大家介绍一下 A1000芯片。A1000芯片里面会有哪些加速器?这些加速器如何去加速激光雷达感知算法?
最后,会介绍一下PointPillars算法。它是目前应用比较广泛的,尤其是在嵌入式领域应用最广泛的激光雷达点云感知算法,在A1000上的部署实现方案。
01
主流激光雷达感知算法比较
首先,我今天主要介绍的几个模型,分别是PointNet、PointNet++、VoxelNet和RangeNet++。

大概看一下它们基本功能。这些模型是目前激光雷达感知中非常基础的模型,相当于是入门必学的模型,涵盖了分类、语义分割、目标检测的功能。这些模型最初可能并不是用于汽车,后续越来越多汽车领域上的人把这些模型应用到汽车领域。随着自动驾驶的发展,像VoxelNet和RangeNet这样的模型,目前也越来越受到大家的欢迎,能够通过语义分割和目标检测,实现前向、机械式360度的分割和目标检测。
下面,我会给大家介绍每个模型具体的设计思路以及优劣点。
首先我们看一下PointNet。
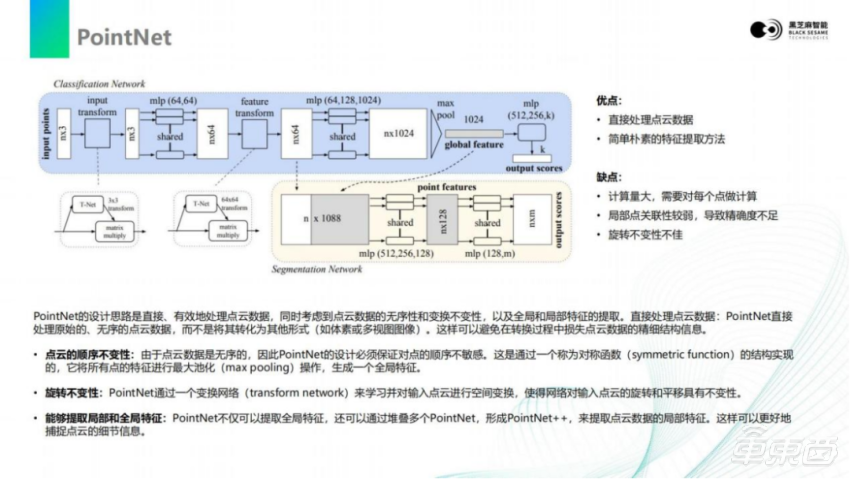
PointNet是目前几个模型里最简单、朴素的方法。它的设计思路比较直接,结构也是最简单的。可以看到上面流程图,描述了神经网络的基本结构。激光雷达反射回的点云是三维的,将点云的所有点排列成一竖列。对于激光雷达来说,它的点是没有顺序而言的,只会描述哪些位置有目标,哪些位置没有目标。对于这些有目标的点,调换顺序并不会影响它的真实含义,不管是正着存储,还是倒着存储,或者交换里面两个点的顺序,对当前场景的表达是不变的。
点云输入之后会经过transform。transform是对点云的旋转,里面会有一个T- Net旋转矩阵,会将输入的点云旋转一定角度,增加它的channel数量。因为对于三维空间的物体,它的旋转并不会影响其分类和类别。所以通过加入这些旋转矩阵,可以增加它的特征丰富程度,进而提高整个模型的识别鲁棒性。(比如杯子)不管这个杯子是横着还是竖着,激光雷达点云感知的算法都应当识别出来。
经过第一次的旋转之后,再次经过了mlp,是一种深度学习里面比较常见的卷积的模型或者说是全连接模型。它能够将这个模型特征的维度进行提升,将三维的数据提升到64维。提升到64维之后,再进行一次 transform,也就是T- Net 的一次旋转,这样能够再次增加更多的旋转特征。得到64维的两次旋转的特征之后,再经过mlp,得到更高的1024维度的特征向量。1024维度的特征向量,在这个步骤利用到顺序不变性,而前面两次旋转的特征增加,利用了它旋转不变性。
对于1024 channel的数据,通过max pooling求最大值的操作,对于顺序是没有任何敏感性的,调换顺序后它的最大值都是相同的。所以这里取max pooling,将特征提取出来,得到1024长度的全局特征,进而得到分类的输出。将全局特征和前面64 channel的数据进行拼接组合,再经过多层的感知全连接或者深度神经网络,最后得到n × m输出的tensor。n × m就是对点云每一个点的分类值,对于n个点,每个点m个类别的打分。
也就是说,PointNet利用了旋转不变性和顺序不变性,从点云数据里面提取出了更高维度的数据。增加了这些维度之后,通过max pooling就可以把提取出来的某个维度中的特征,通过取最大值的方式取出来,这样可以得到目标的类别。PointNet的处理是比较直接,便于理解的,是目前这些模型里面最简单朴素的特征提取方法。
但是这种方式本身的计算量是很大的,因为激光雷达返回的点的数量是非常多的,可能多达上万或者上百万个点,上百万个点进行旋转、卷积、升维一些操作,会对计算量带来非常大的负担。并且像一个这样的朴素的计算方法,它的精度其实并不非常优秀。虽然它对特征的确进行了升维,但对于升维之后局部关联性的损失并没有补回,导致有一些精度的损失。这是所有激光雷达算法里的一个基础算法。
刚才大家也看到,后面会有一个算法叫PointNet++,它是对PointNet基础之上的改进和提升。我们可以看一下PointNet++。
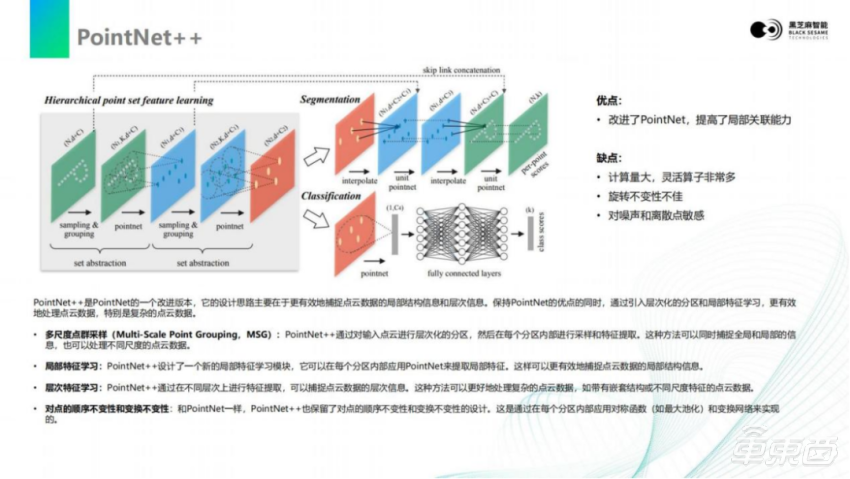
对于PointNet++,可以看到这个图会比刚才更复杂一些,实际计算会比看到的这个图更复杂。原因是在于它把刚才的PointNet已经嵌入到这个流程里面,可以看到在画面里面,有一些PointNet的箭头,每一次PointNet箭头都是对图像进行一次PointNet计算,这样基本上包含了前一页整个PointNet计算流程。
此外,PointNet++最主要是有几个特点。
第一点,它对于整个的计算过程,加入了采样和分组。它按照一定规则将邻域的一些点,挑选为代表性的点,基于代表性的点进行PointNet计算,这样可以对一些噪点或者特殊点进行抑制。
另一个特点是,对于PointNet++使用了skip link的concat。它把前端计算的feature和计算到后端的 feature进行concat,可以把最原始的信息和卷积之后的信息,进行组合。这样它既拥有了提升维度以后的分类或语义的信息,同时也带有了未经过卷积处理的原始相邻数据,没有进行大量变换的位置关系。基于这些位置关系,可以把整个点云图像里面的目标进行分割和分类。比如,同样对于 PointNet下采样之后,还会进行上采样,上采样以后与输入的feature层进行拼接之后,得到主点的分类结果,或者说是分割结果。分类主要是走下面的支路,因为上面如果做分割需要做上采样,需要做差值。分类主要是通过全连接的网络对分类结果的进行输出。
这样的模型一方面拥有PointNet特征提取能力,另一方面又基于多次的PointNet以及跨层的连接,提高了局部的关联能力,将这些局部的关系保留下来。但是一个这样的模型大家也能看出来,它的计算量非常大,不仅仅是PointNet的4倍,甚至还需要更多的采样和拼接的过程。这些过程对于计算是非常不友好的。大家应该也经历过一些像 GPU或者CPU编程,越复杂的计算对于计算时间的开销会越长。所以,PointNet++对于嵌入式的部署,其实不是很友好的。
再往下是RangeNet++。
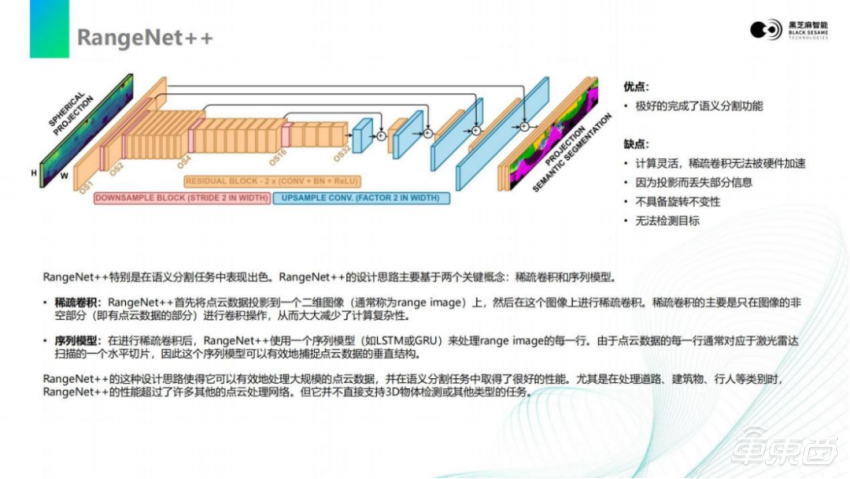
RangeNet++的思路和前面PointNet不一样,激光雷达的点云扫描出来返回的点云结果,本质上是可以做成投影图像的。可以看到画面里面左上角这张图,如果把激光雷达扫描的范围当做一个画轴去展开,可以投影到一张2D的图上,但在这张图上的这些点是比较稀疏的。对于这些稀疏的点,RangeNet++使用了稀疏卷积。如果要去做稠密卷积就会发现,它的计算量是非常大的,整个图像的分辨率会非常大。同样的,它使用传统CNN的思路,对输入的激光雷达数据做成一张图像的二维的数据,进行下采样,并且使用残差的组件,构成了下采样的结构。同时,仍然会有一些前端的初级feature,向后端传递和后端组合,在后端也会逐步上采样做解码。最后,推理出语义分割的结果,对每一个像素进行分割。
此外,它对输出模型的结果,仍然还会再做一次LSTM之类的序列模型。因为对于激光来激光雷达来说,它的输出是有一个时间序列的变化历程的。所以再增加一次LSTM,对于语义分割的结果来说,效果会更好。
RangeNet++完成了语义分割的功能。但是除了语义分割以外,在自动驾驶里面,目前最重要的还是目标检测。后续大家如果需要语义分割,可以参考RangeNet++的做法。但是,类似于这种大规模的LSTM,其实很难部署在嵌入式平台上,除非是GPU。因为绝大多数目前的嵌入式AI芯片,都是基于CNN结构设计的,对于这种RNN结构的模型,其实并不友好。
然后我们看下VoxelNet。
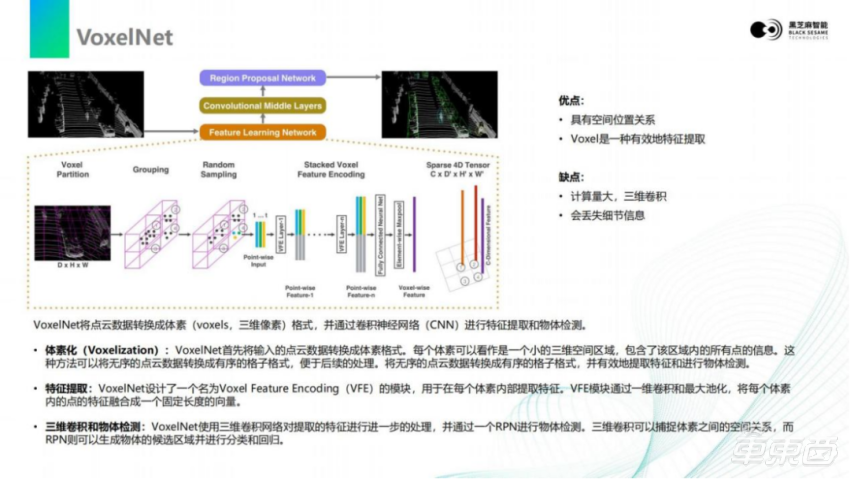
VoxelNet目前相当于是PointPillars的前身,或者说是它的标准版。VoxelNet的思路是将点云空间,划分成一个个长方体的网格。每一个网格里的点,转化成体素(Voxels,三位像素)的形式,把它转换成一种数字排列方法;并且进行Voxel的编码,比如提取它的最大值、最小值,距离中心点的距离等一些信息,把这些信息构成网格的特征。整个空间会划分成三维的网格结构,每一个网格结构都会带有这样的一个向量,最后形成四维的空间向量,且四维空间向量是稀疏的,有的地方没有点。VoxelNet后面对四维的空间向量进行卷集,通过RPN目标检测架构,把提取出来的特征转换到CNN里去,最后输出这个目标框。
VoxelNet的好处有:首先,它是一种能够非常有效地提取3D点云在空间中位置信息,或者多个点之间位置信息的方法。而且,它能够保留这些点和点之间的空间位置关系,但是这个模型需要三维的卷积。如果大家对图像接触比较多会知道,图像基本上是二维卷积。三维卷积对于目前AI芯片加速,其实是不友好的。目前支持三维卷积的并不多,即使支持,效率相对也比较低,这就是VoxelNet。
基于VoxelNet,目前行业里面用的最多的是PointPillars。它是由VoxelNet简化而来。它对点云的空间,并不划分成空间网格,空间网格可能会有高度,是一个3D的空间,再加上向量的维度可能会达到四维。
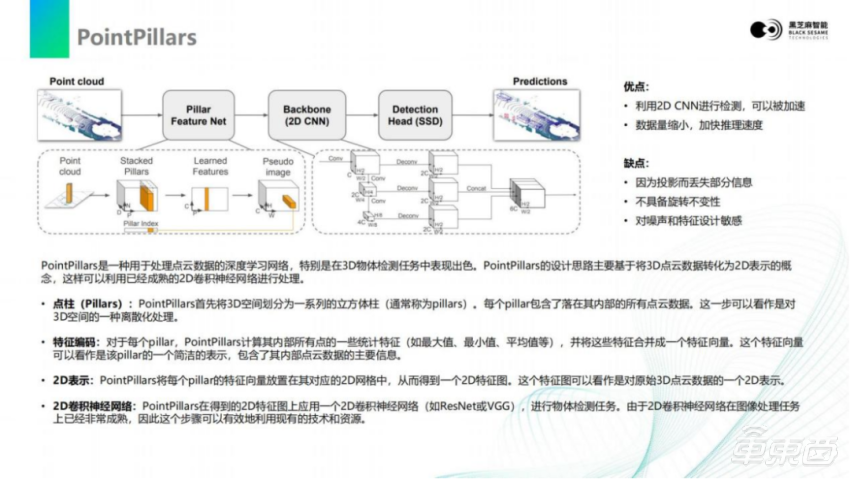
PointPillars是把空间划分成一个个柱子,叫做pillars。然后对柱子以内的点进行统计,比如它的最大值、最小值、距离等等一些信息,将这些信息作为 pillars的特征向量。pillars的整个画面空间基本可以构成一个2D的平面,因为它划分成一个个柱子,每个柱子就是一个向量,所有数据都转换成3D的向量,这样就可以用2D CNN的卷积方法去做处理。
回到流程里面看,整个PointPillars会分成几个阶段。第一阶段是pillar的feature提取,第二阶段就是Backbone的提取、计算,通过CNN的方式对特征进行提取,然后通过SSD的方式,对目标框进行选取。这样的模型结构,目前对市面上主流的神经网络加速器是非常友好的。首先它使用的是2D的CNN,这样的加速器可以很好的加速神经网络,输出的是SSD,这样会减少二阶段的复杂程度,也避免stm等计算的复杂。这是PointPillars,后面我们会更具体去讲PointPillars各个环节如何map到嵌入式芯片里面。
02
黑芝麻智能华山®二号A1000芯片
内的加速器解析

下一步给大家介绍一下A1000芯片大致的框图。在这个图里大家可以看到各种颜色的核心。这些核心都在一个芯片里面。大家可以看到,右面会有一些芯片的指标,比如A1000具有8个A55的核心,A55的核心可以运行到1.5GHz,是比较强的CPU处理器。同时,芯片里面还带有Safety island绿色的部分,有一个双核的R5,当然这里面还带有一个信息安全的R5核心,这是一个Safety的功能安全岛。
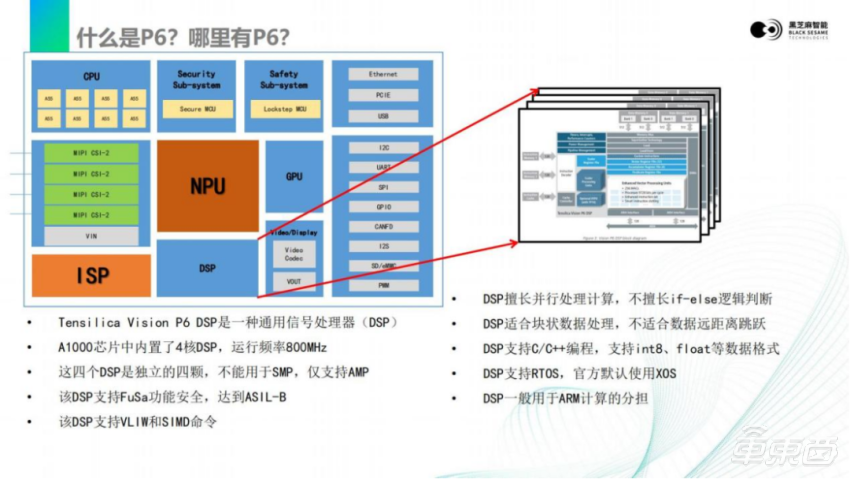
右下角大家可以看到DynamAI NN是一个神经网络推理加速器,可以运行在800 MHz或1GHz的频率上,里面有很多卷积加速器。A1000芯片作为一个域控制器,还带有一个GPU。待会要讲到一个细节是,我们芯片里面带有非常多的DSP,整个芯片会有5个DSP。这5个DSP,1个是位于深度学习里面,4个是位于外面独立的。
这颗芯片还带有ISP的输入。内置的ISP能够处理最多16路的图像。我们内部还带有图像处理的加速器(加速引擎),在接口方面支持MIPI接口,支持两路千兆以太网,支持摄像头的MIPI输入、并口输出。对于图像,我们带有H.264、H.265的压缩。对于DDR,有双通道的DDR4,用于开发调试的USB以及大容量硬盘连接的 PCIE,这是芯片的基本结构。
接下来讲一下和激光雷达感知有关的几个模块。
一个是刚才提到的深度学习加速器—DynamAI NN。深度学习加速器是黑芝麻智能自研的一个神经网络的推理引擎。这个引擎里包含了像卷积加速器、全连接加速器、EDP非线性计算的加速器,以及一个灵活可编程的DSP。这样的构成使得神经网络加速器,既可以完成卷积的计算,也可以加速全连接,加速非线性的激活函数,还支持灵活的自定义算子,或者说是灵活算子在DSP上,或者调度在DSP上。
整个加速器支持混合精度,像int4、int8都是支持的,对于特别的层可以支持到 float。整个加速器是支持稀疏化的,如果对神经网络进行一些稀疏化的训练,可以得到成倍的算力提升。我们待会所讲到的PointPillars里面的CNN部分,都会运行在DynamAI NN上面。
下一个是刚才提到的DSP,是激光雷达点云处理的算法,在嵌入式端部署好或坏的一个关键点。

在我们芯片里面内置了4颗独立的VisionP6 DSP,是一个向量化DSP,支持SIMD,支持64路并行,64个int8同时计算。如果用int8来做深度学习,每一颗DSP等效0.4TOPS的算力。
DSP的编程和传统的MCU或者CPU是类似的,它支持C/ C++的编译器,并且这个编译器支持功能安全。DSP是支持SIMD的,也就说可以像ARM NEON一样,调用一些汇编及指令去加速加速向量化的处理。因为,对于点云的处理或者图像的处理,绝大多数的数据都是向量化的,比如说机械性、并性的、没有太多逻辑的,或者可以先通过搬运,让这些数据对齐,再由向量化进行处理。DSP同时也支持Caffe和Tensorflow。
此外, DSP上还可以运行一些常见OpenCV算子,像一些Sobel 算子、直方图计算、阈值的获取、角点提取等,这些常见的CV的算子基本上都在DSP上有专门的优化实现。
03
PointPillars算法
在A1000上的部署实现
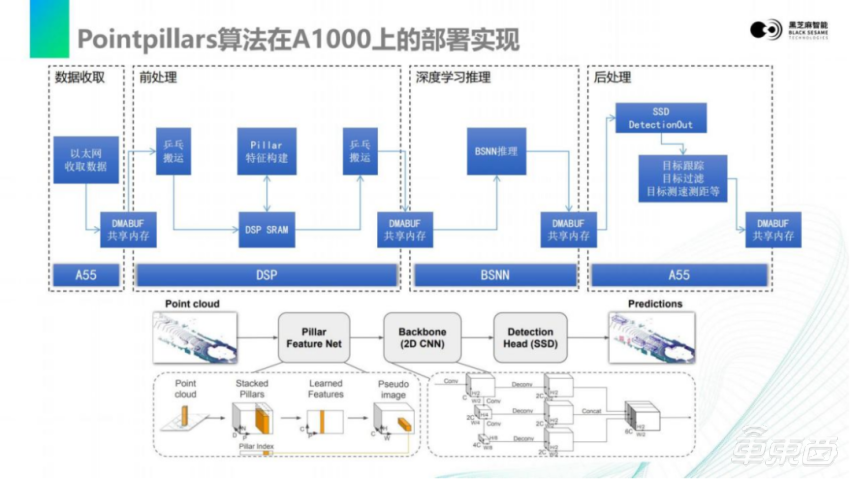
回到刚才讲的Pointpillars算法。这个算法刚才从论文里的图里也看得很清楚。激光雷达的数据通过以太网收取下来之后,我们通常会把它放到共享内存里面去。这个共享内存来源于Linux的DMABUF的形式,对于像DSP、DynamAI NN或者其他的加速器,它能访问的内存必须是连续地址内存,所以必须使用DMABUF的内存,这样才可以实现零拷贝,在任意两个核心之间传递。
以太网数据收取下来之后,可以通过ping-pong搬运,在DSP里实现对数据的搬入,搬到DSP内部的SRAM里去。DSP的SRAM,待会讲细它的重要性。DSP内部有一个很小的区域,但这个很小的区域的速度非常快,所以通常会把要处理的数据先搬到SRAM里面去,再由DSP进行计算,在DSP上进行Pillar特征构建,形成Pillar特征向量。
基于这个特征向量,就可以把它搬到 DMABUF中,DMABUF就可以交给深度学习DynamAI NN,做模型的推理。在DynamAI NN上做模型推理,需要去获取黑芝麻智能DynamAI NN工具链。可以将训练出来的模型转换成ONNX,使用黑芝麻智能的工具链,将ONNX模型转换成黑芝麻智能的bin文件或者lib文件,这样就可以加载到芯片里DynamAI NN加速器上去做推理。当转换好模型以后,将输入的tensor传递给DynamAI NN,DynamAI NN就会吐出结果,不需要关心中间的过程,也不需要关心刚才讲到DynamAI NN里面复杂的加速器。整个DynamAI NN的驱动和推理框架,会照顾好所有模块的调用和加速。只需要把tensor传递进去,再把tensor传递出来。DynamAI NN推理出来的buffer,本质上也是一个共享内存,也可以在多个核心之间传递。
最后一个环节是A55的处理,理论上它也是可以放到 DSP上去做。在后处理这一端,通常要做的是神经网络的检测头的计算,因为DetectionOut层,更多的是逻辑处理,是对目标的排序或者筛选。最后,可以根据自动驾驶或者是一些功能需求,对目标进行跟踪、过滤,然后对目标进行测距测速,实现激光雷达目标检测最终功能的表现。
P6的DSP上其实运行的是RTOS,默认使用的是叫XOS,本质上是一种RTOS——是一个实时操作系统,可以在DSP上使用浮点、int8等,做C/C++的编程。在使用DSP的时候,ARM的资源是完全不会被占用的,所以大量的计算可以由DSP去替代ARM进行分担。很多项目大家做到最后就会发现,ARM的资源是相对比较紧张的,因为所有人都想用ARM,ARM的编程是最简单的。
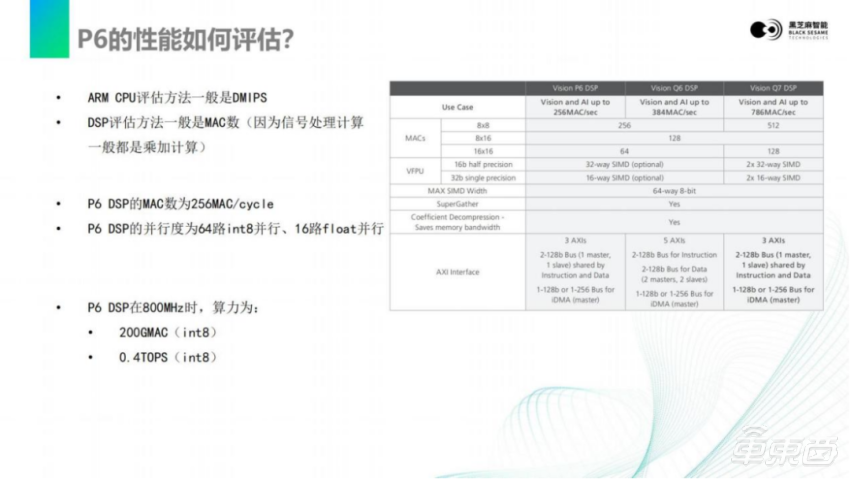
对于DSP来说,我们一般评估算力的方法是通过MAC数,大家如果了解其他芯片的DSP,其实做法是类似的。DSP最擅长的事情是乘加,两数相乘再加上第三个数。因为信号处理里面最主要的是乘加计算,P6 DSP具有256 MAC/cycle,每个时钟周期都可以做256次乘加运算,一次乘加等于两次运算(一次乘一次加)。可以对它乘以2得到ops,在800M时可以换算成0.4TOPS的算力。
刚才讲到 P6可以做CV加速,以及像刚才讲的Pointpillars前处理加速。

此外,P6自带DMA,可以做DMA搬运。大家可以发现,在ARM上做memory copy是有CPU性能开销的。当你需要搬运固定数量内存的时候,用DMA可能会更高效一些,可以减轻ARM的资源开销。P6可以做一些小规模深度学习,比如一个非常小的MobileNet之类的模型,可以在P6上运行。
在P6上DSP如何去开发?

我们提供了P6上的SDK,基于这个SDK,可以很轻松地在Linux上调试DSP。这个SDK我们叫做RCALL,而RCALL来源于Remote Call,类似于远程过程调用。可以从Linux调用API,由驱动传递给DSP,等到DSP运算完成以后,再返回给Linux。对于使用者来说,相当于是在Linux上调用了DSP,返回了结果。所以在这样的框架下,开发将会非常简单。
我们也对比了同行业的像OpenVX等一些做法,本质上P6 DSP是支持OpenVX的。但经过我们评估发现,OpenVX上手难度、开发复杂度以及调试难度都非常大,所以我们抛弃了OpenVX,使用了自己设计的RCALL的方式。大家可能会认为OpenVX的可移植性比较好,但最终用起来时的可移植性并没有很高。因为每个平台都有其定制化的API,在移植的时候会有很大差异,且每个加速核心在不同平台之间的算力差距也不同,很难完全平行地移植过来。
所以对大家的建议是:基于 P6 DSP进行开发,首先最好是能够去跑通RCALL里自带的demo程序。进阶是可以在RCALL里加入一些自己的demo,去做一些自定义开发。当你熟悉了DSP开发以后,可以先在PC上进行仿真运行DSP程序,将DSP程序优化到最佳以后,再把这个程序放到板子上跑,这样做的开发效率和优化的程度是最高的。

如何去划分任务?像Pointpillars,并不是每一次运算都要去从Linux去调用Pointpillars,指的是一帧图像里的每一次操作,最好是基于帧单位的调用,每一帧调用一次DSP。不管是通过ROS还是Cyber,在ARM这一端都可以将DSP封装成一个算子或node。每一次片间通信通信,从ARM到DSP,都有可能会增大系统的负载,所以每一帧前处理,调用一次。
说到 DSP开发,如果是从专业DSP开发,推荐是在PC上的模拟器环境进行开发。因为在模拟器环境开发,可以确保和板端完全一致的计算结果,并且可以更高效的进行调试。后面我们会具体讲解 local memory的使用。

我们默认在RCALL里面提供了这些列出来的常见的算子,比如图像金字塔、图像畸变、图像旋转、图像拷贝,像一些浮点运算、颜色空间转换、双目视觉等一些算子,都可以在 DSP上运行。

刚才又讲到 DSP存储架构,DSP会分成多级存储。刚才讲到DDR和local memory。local memory会有256k的内存,非常小。但是对于片内,这样一个存储区域已经很大了,通常需要把输入数据分成上千片或者上万片,由DMA搬运进来,由DSP去读写local memory。如果让DSP去直接读写DDR会发现,相对于local memory它的速度会非常慢。

另一方面就是内存管理。刚才也有提到,我们需要使用DMABUF的方式来传递图像或者零拷贝的数据。右面是我们内存的划分,在2GB以内(0~2GB)这段区域内,我们会保留对应区域的内存,这些内存可以用来申请DMABUF,用于核心与核心之间的、零拷贝的数据传递,这些内存都可以通过API的形式申请。

对于DSP,官方也提供了非常多的加速库,像Eigen、SLAM、sin/cos/tan之类的一些数学计算库;还有一些图像的计算库,例如libxi图像计算,一些OpenCV相关的算子的加速。TileManager是对数据分割和搬运,也就是刚才讲到DMA如何把图输入数据进行分割,搬运到内部local memory及搬出的加速库。
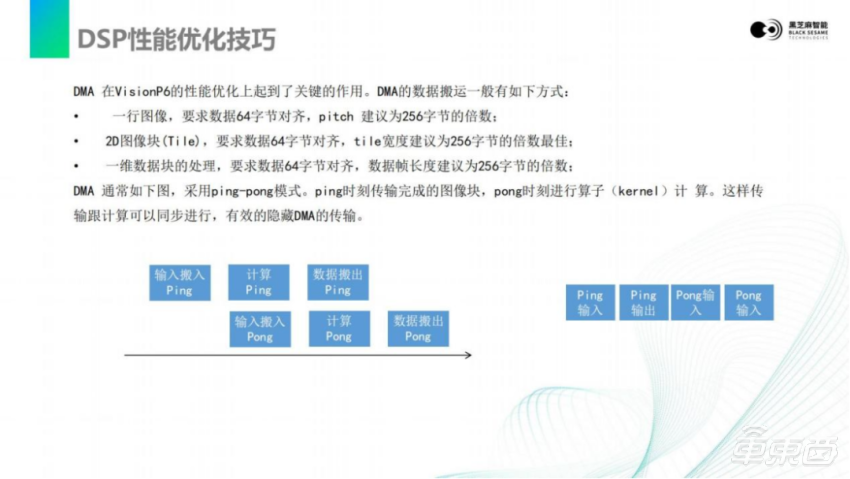
刚才也有提到ping-pong搬运,可能有的同事不是很清楚。数据搬运和DSP是可以并行的,可以让DMA在搬运一段数据的同时,让DSP计算另一段数据。这样计算和搬运就可以完全并行,实现计算能力满载。
当然,DMA搬运是有一定数据对齐的要求,这也是嵌入式领域大家需要注意的,和PC完全不一样的地方。最终可以通过ping-pong的方式,实现算子和计算的并行,隐藏 DMA传输的时间。

更深一步就是指令级的优化,这样就需要去阅读VisionP6的用户手册。它里面会指导你如何去做,有哪些这种向量化指令?这些向量化指令如何去减少指令的数量?将以前可能要读取8次的访问,变成读取1次。还有如何去约束你的数据,进行地址对齐,这样才可以使用向量量化并行。这是DSP的优化部分。
今天有关激光雷达感知算法在A1000的部署,就介绍到这里,谢谢大家。



-

凤凰网汽车公众号
搜索:autoifeng

-

官方微博
@ 凤凰网汽车

-

报价小程序
搜索:风车价


.png)
大家都在看







趣图推荐
.png)